
코딩하는 해맑은 거북이
[선형대수학] 인공지능을 위한 선형대수 (10) - 끝 본문
본 게시물의 내용은 '인공지능을 위한 선형대수(주재걸 교수님)' 강의를 듣고 작성하였다.
해당 글은 아래의 8가지를 다룬다.
1. 특이값 분해(Singular Value Decomposition)
2. 스펙트럴 정리(Spectral Theorem)
3. 대칭행렬(Symmetric Matrix)
4. Positive Definite Matrix
5. 주성분분석(Principal Component Analysis)
6. 그람행렬(Gram Matrix)
7. Low-Rank Approximation
8. Dimension-Reducing Transformation
- 특이값 분해 Ⅰ

- 특이값 분해(Singular Value Decomposition, SVD)
: 직사각행렬 A를 대상으로
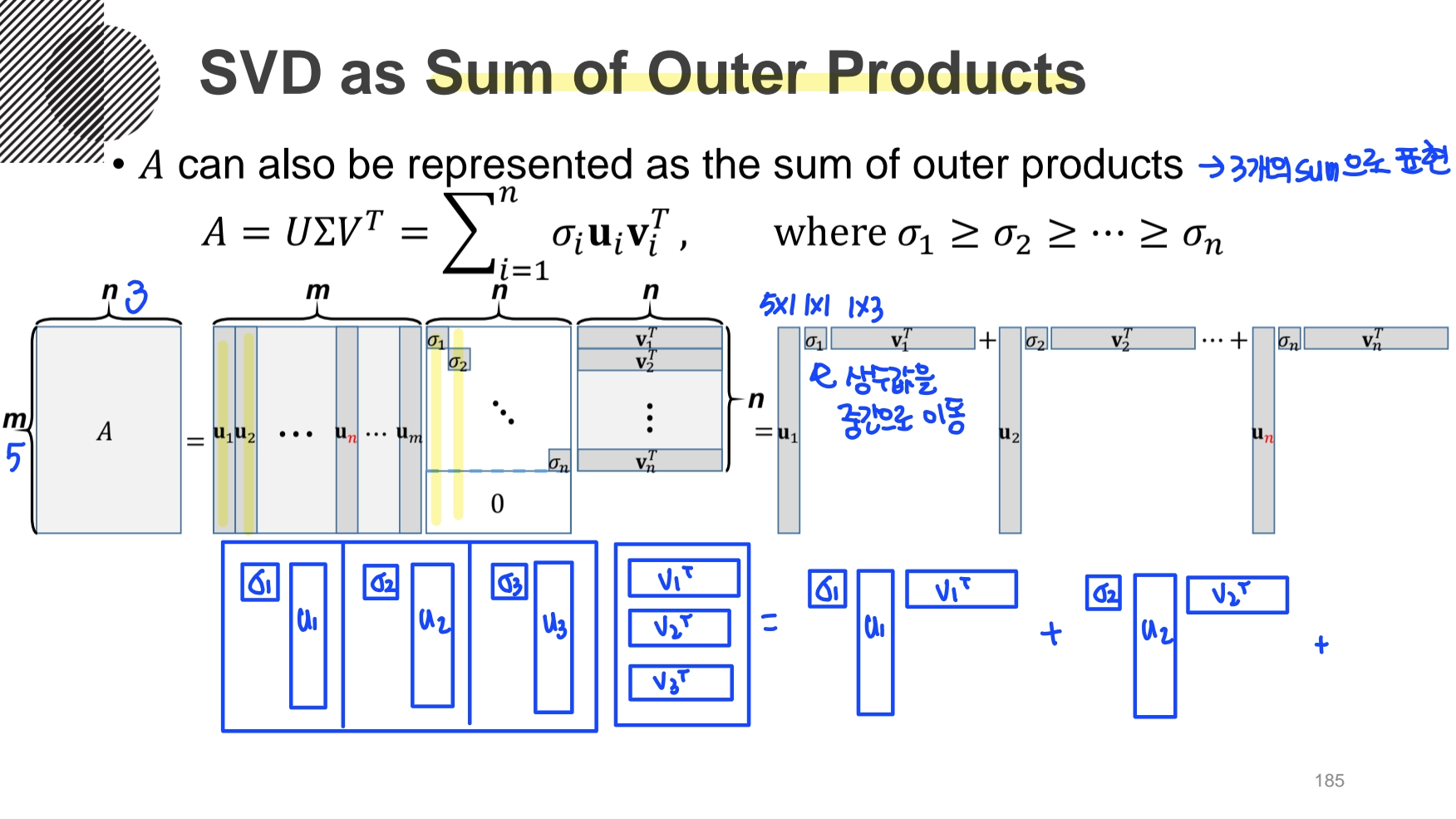
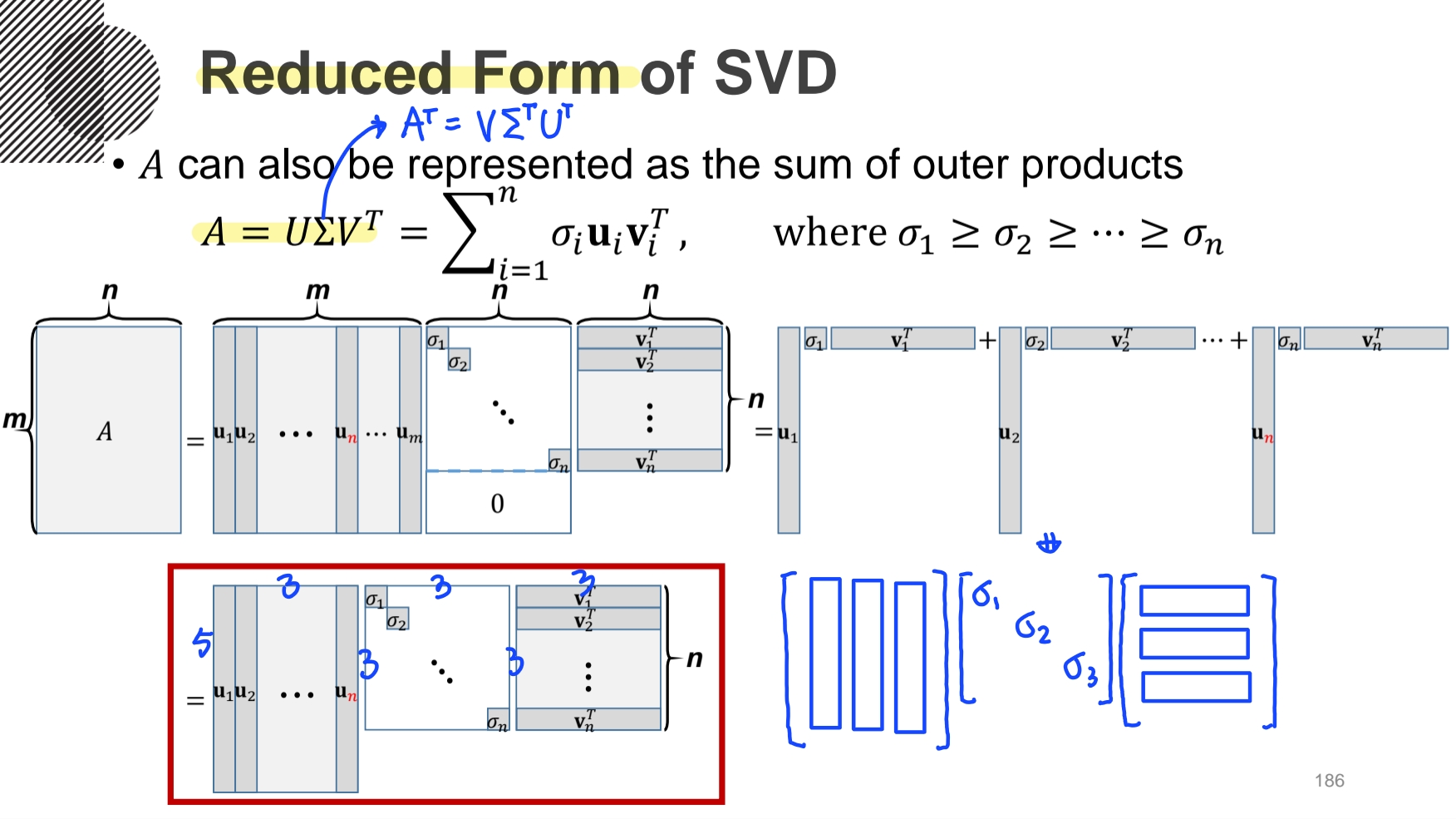
그리고, 이것을 선형결합으로 다시 표현해보면, Reduced Form 하게 표현된 걸 볼 수 있다.

Gram-Schmidt orthogonalization을 사용해서 A,
그런데, orthonormal basis가 유일하지 않다. 왜냐하면, Gram-Schmidt orthogonalization 방법은 순서에 맞게끔 진행이 되는데, 순서가 변동되면 결과값도 달라지기 때문이다.
그래서, AV = ΣU = UΣ (Σ행렬의 상수값 σ는 순서 상관없음) 의 특정한 조건을 만족시키는 orthogonal basis를 찾는 방법을 사용한다.
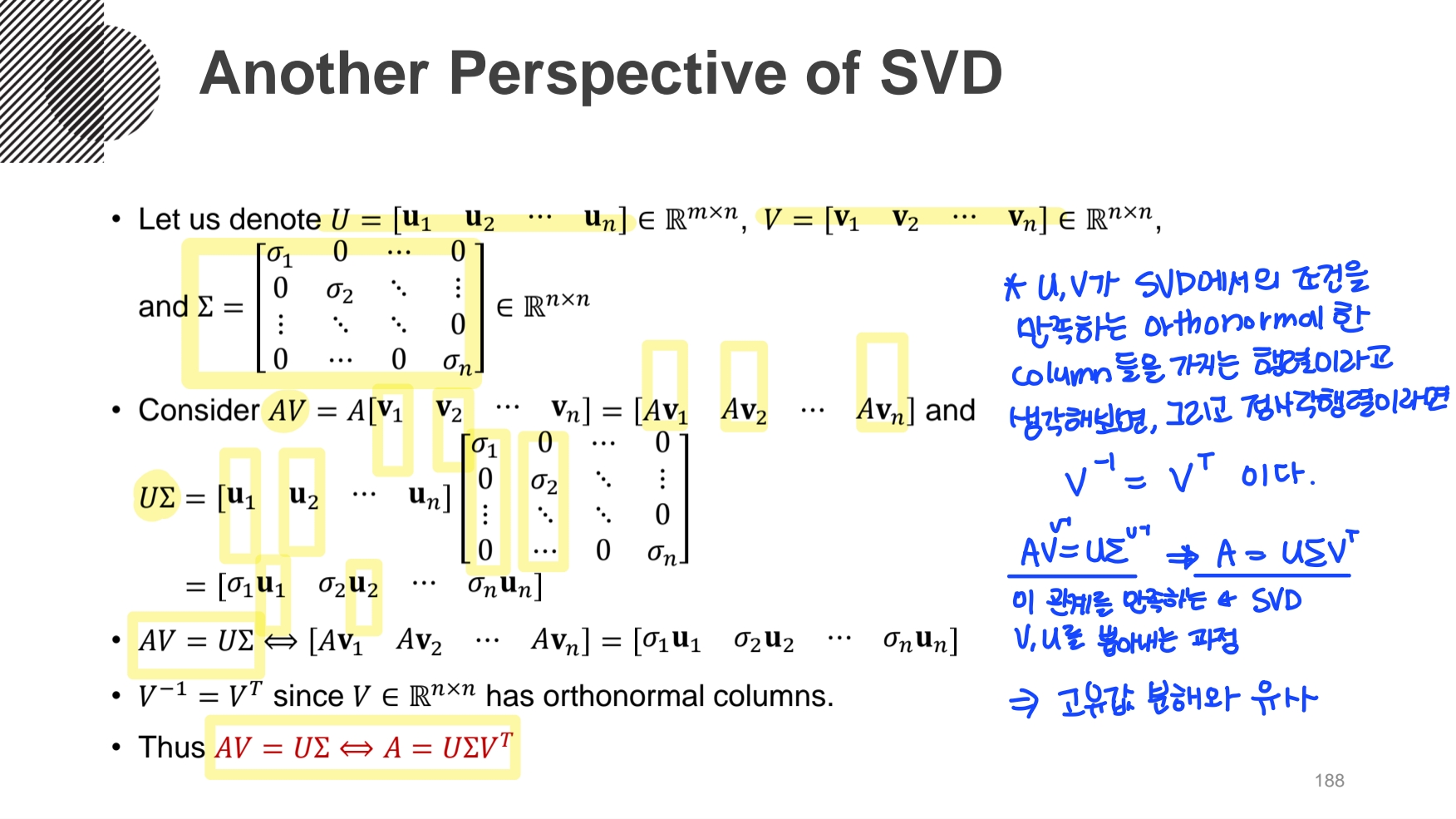
\(AV=UΣ\)의 식 양변에
- 특이값 분해 Ⅱ

SVD를 계산하기 위한 알고리즘이 따로 있는 것이 아니라, 안을 들여다보면 eigendecomposition(고유값분해)으로 푸는 것이다.
다만, 여기서 아래의 3가지 조건을 만족하는 U, V, Σ를 찾을 수 있어야 한다.
1) Spectral theorem :
2) Positive definite :
3)

- Symmetric
: 행렬의 대각선을 기준으로 데칼코마니인 것을 의미한다.
Symmetric은 행렬 A를 전치해도 똑같은
Symmetric 행렬 S는 항상 diagonalizable 가능하다. 즉, eigencomposition이 무조건 존재한다.
그리고 고유벡터들은 선형독립이고, orthogonal 하다.

- Spectral Theorem
: Symmetric 행렬 S를
Symmetric 행렬 S는 n개의 실수로 이루어진 고유벡터를 가진다. (중근포함) 그리고 이는 orthogonally하게 diagonalizable 가능하다


- Positive Definite Matrice
: 정사각행렬 A가 있을 때,
- Positive semi-definite Matrice
: Positive Definite Matrice에서 0이 될 때도 포함되는 것을 의미한다.

행렬 S가 symmetric하고 positive-definite하다면, Spectral decomposition이 가능하다.
그리고 여기서 모든 고유값은 양수가 된다.

따라서, orthogonal eigenvector로 구성된 U, V 행렬을 구성할 수 있고, S의 Eigenvalue들이 모두 양수로 구성되어 있음을 알 수 있다.

- 어떤 직사각행렬이든 SVD는 항상 존재한다.
- 어떤 정사각행렬은 Eigendecomposition이 없을 때도 있지만, SVD는 항상 존재한다.
cf) Eigendecomposition은 정사각행렬에서만 정의 가능 했음.
결론 : 주어진 행렬이 Square, Symmetric, Positive-(semi-)definite 조건을 만족한다면, Eigendecomposition이 항상 존재하고, Eigendecomposition와 Singular Value Decomposition은 사실상 같은 역할을 한다.
- 고유값 분해와 특이값 분해의 응용

머신러닝에서 우리가 다루는 데이터는 Symmetric positive-(semi-)definete matrix인 경우가 대부분이다.
feature(키, 혈액형, 몸무게)-by-data item(사람)인 행렬 A를 생각해보면
이러한 유사도와 상관계수를 통해 PCA(pricipal component analysis)를 진행할 수 있고,
style transfer을 해결할 때 Gram matrix을 사용하는데, 이게
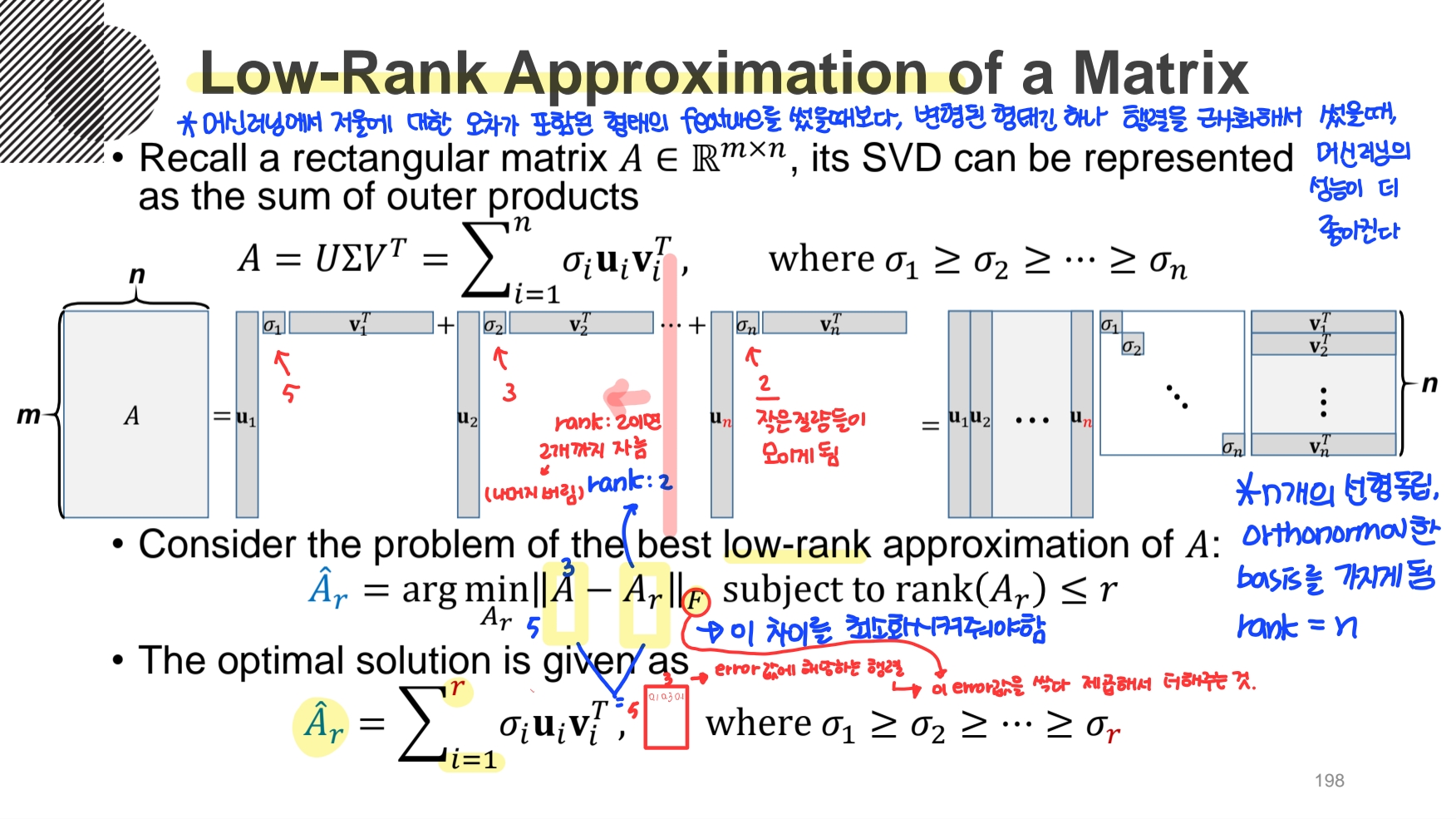
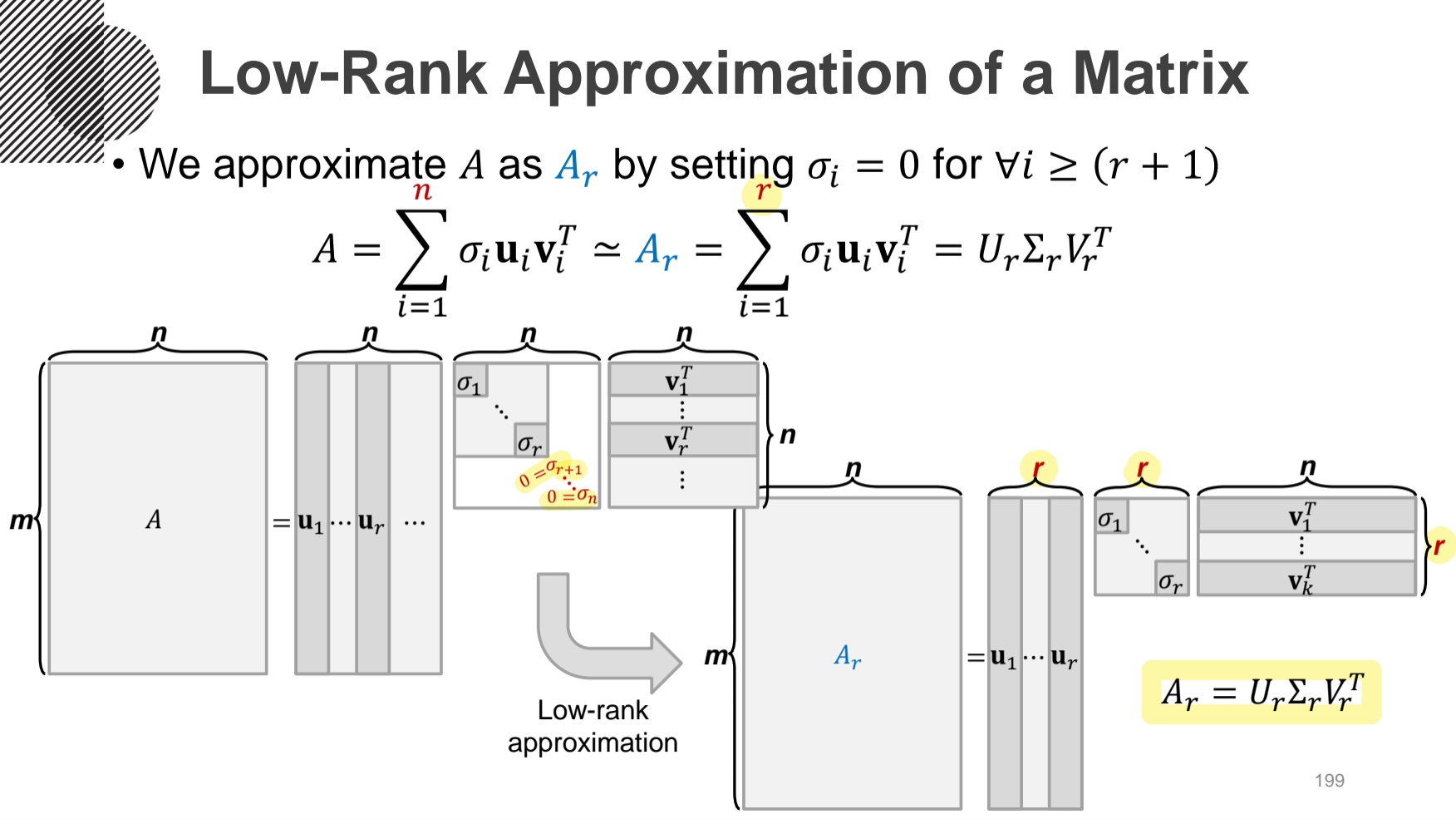
앞에서 SVD를 Sum of Outer Product로 Reduced Form 하게 표현될 수 있었다. 이때 발생하는 문제는 Low-Rank Approximation 이다. 이는 행렬의 Rank에 제약을 두면서 원래의 행렬과 가장 비슷한 행렬을 찾는 문제이다. 근사한 행렬이 원래의 행렬과 얼마나 비슷한지는 Norm을 사용해서 구하며, 이 차이를 최소화해주어야 한다. 식은 위와 같다.
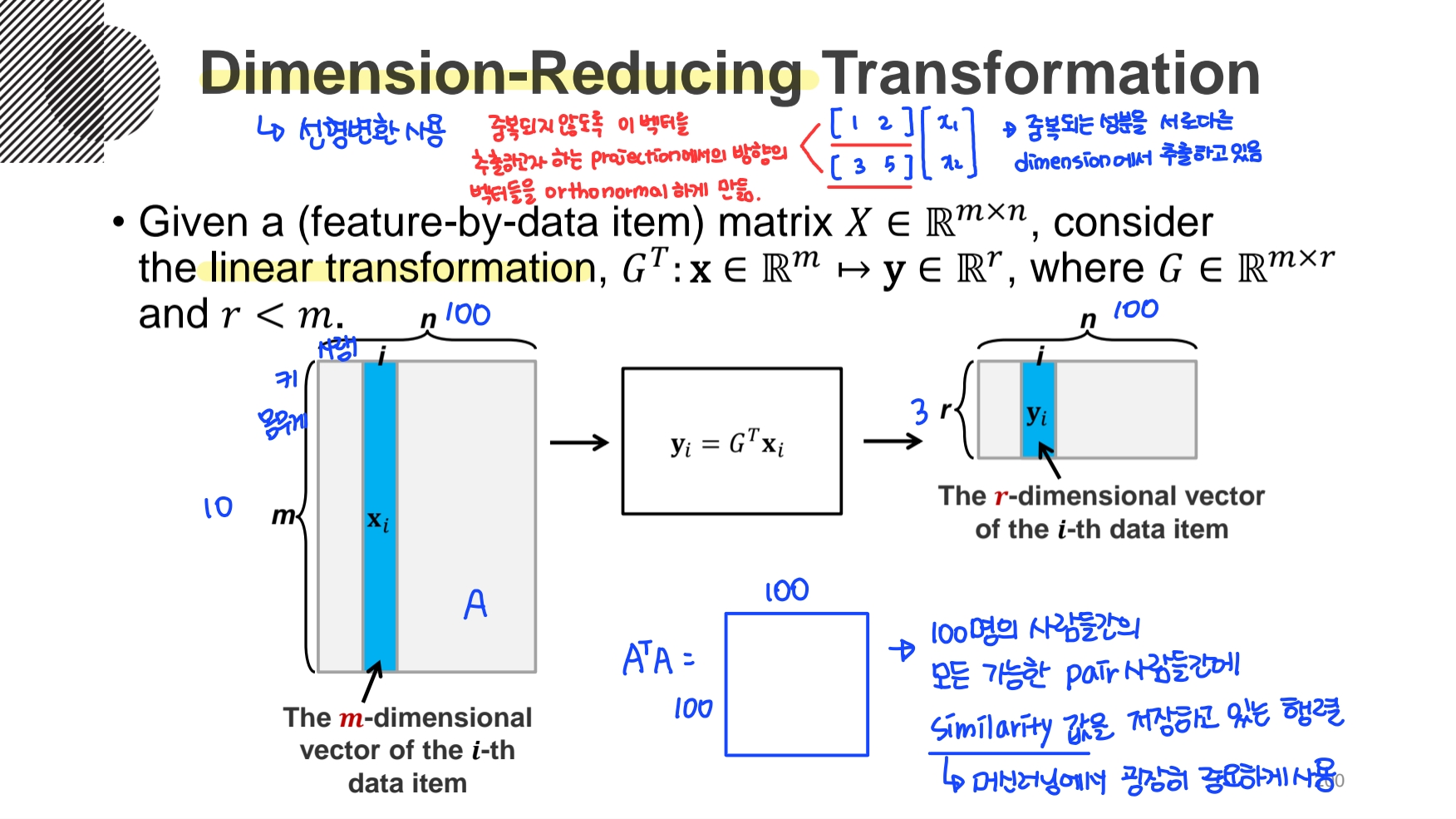
feature-by-data item 행렬 X(mxn)를 m개의 feature에서 r개의 feature만 사용하도록 줄이는 것을 Dimension-Reducing Transformation 이라 한다. 이때 변환은 선형변환을 사용한다.

보통 어떤 Feature의 두 열의 정보가 대게 중복되어 있으므로, 이러한 중복된 정보를 제거하기 위해서는 orthonormal하게 만들어서 pairwise similarity를 가장 잘 보존하도록하는 차원축소된 버전의 표현형을 얻으면 된다. 식은 와 같다.


SVD는 PCA, Topic modeling, word2vec, gram matrix 등 많은 분야에서 사용되고 있다.
'Mathematics | Statistics' 카테고리의 다른 글
| [확률및통계] 독립사건과 확률 (0) | 2022.07.27 |
|---|---|
| [확률및통계] 조건부확률과 Bayes 정리 (0) | 2022.07.26 |
| [선형대수학] 인공지능을 위한 선형대수 (9) (0) | 2022.07.22 |
| [선형대수학] 인공지능을 위한 선형대수 (8) (0) | 2022.07.21 |
| [선형대수학] 인공지능을 위한 선형대수 (7) (0) | 2022.07.20 |



