
코딩하는 해맑은 거북이
[데이터분석] 대구 교통사고 데이터 분석하기 본문
본 게시물의 내용은 데이콘의 '대구 교통사고 피해 예측 AI 경진대회'에 참여하여 데이터를 분석해본 결과 일부를 기록한 것이다.
해당 글은 아래의 내용을 다룬다.
📢 사용 데이터셋 정보
💡 데이터 로드 및 확인하기
💡 데이터 요약정보 살펴보기
💡 결측치 확인하기
💡 데이터 전처리하기
💡 외부데이터 가져오기
💡 데이터 시각화 및 인사이트 도출
🎈 Github
데이콘(Dacon)의 '대구 교통사고 피해 예측 AI 경진대회'의 대구에서 발생한 교통사고 데이터셋을 사용하였다.
대구 교통사고 피해 예측 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
해당 대회에서는 시고 발생 시간, 공간 등의 시공간 정보를 활용하여 사고위험도(ECLO)를 예측하는 AI 모델을 개발하는 것이다. 따라서, 시공간 정보 데이터가 ECLO와 관련이 있다고 가설을 세우고 분석을 진행해보았다.
※ ECLO(Equivalent Casualty Loss Only) : 인명피해 심각도
- ECLO = 사망자수 * 10 + 중상자수 * 5 + 경상자수 * 3 + 부상자수 * 1
- 본 대회에서는 사고의 위험도를 인명피해 심각도로 측정
- train.csv
- ID : 대구에서 발생한 교통사고의 고유 ID
- 2019년부터 2021년까지의 교통사고 데이터로 구성
- 해당 사고가 발생한 당시의 시공간 정보와 사고 관련 정보 포함
- ECLO : 인명피해 심각도
- test.csv
- ID : 대구에서 발생한 교통사고의 고유 ID
- 2022년도의 교통사고 데이터로 구성
- 추론 시점에서 획득할 수 있는 정보로 구성
데이터를 로드하고 shape를 통해 train 데이터는 (39609, 23)의 행과 열로 이루어져 있고, test 데이터는 (10963, 8)의 행과 열로 이루어진 것을 확인할 수 있다.
import pandas as pd
pd.set_option('display.max_columns', None) # 모든 열 출력
train_org = pd.read_csv('data/train.csv')
display(train_org.head())
test_org = pd.read_csv('data/test.csv')
display(test_org.tail())
display(train_org.shape)
display(test_org.shape)
df.info()를 통해 컬럼들(Column)과 각 컬럼들의 데이터 타입(Dtype), 메모리 사용량 등을 확인할 수 있다. 또한, Non-null의 갯수도 확인해보니 train 데이터 일부 컬럼에 결측치가 있는 것으로 보인다.
train_org.info()
test_org.info()
train 데이터의 결측치의 개수를 확인해보니, 피해운전자 관련된 컬럼에서 991개의 결측치가 확인되었다. 하지만, test 데이터에는 피해운전자 관련 컬럼은 없어 모델 학습시에 사용되지 않으므로 문제가 없을 것으로 보인다.
train_org.isnull().sum()
✔️ 파생 변수 생성1: 날짜, 시간정보 생성
연도-월-일 시간(ex. 2019-01-01 00) 형태로 이루어진 '사고일시' 컬럼으로 부터 '연도', '월', '일', '시간'을 분리하여 새로운 컬럼을 생성해준다. 그리고 '사고일시' 컬럼은 삭제해준다.
train_df = train_org.copy()
test_df = test_org.copy()
time_pattern = r'(\d{4})-(\d{1,2})-(\d{1,2}) (\d{1,2})'
train_df[['연', '월', '일', '시간']] = train_org['사고일시'].str.extract(time_pattern)
train_df[['연', '월', '일', '시간']] = train_df[['연', '월', '일', '시간']].apply(pd.to_numeric) # 추출된 문자열을 수치화해줍니다
train_df = train_df.drop(columns=['사고일시']) # 정보 추출이 완료된 '사고일시' 컬럼은 제거합니다
# 해당 과정을 test_x에 대해서도 반복해줍니다
test_df[['연', '월', '일', '시간']] = test_org['사고일시'].str.extract(time_pattern)
test_df[['연', '월', '일', '시간']] = test_df[['연', '월', '일', '시간']].apply(pd.to_numeric)
test_df = test_df.drop(columns=['사고일시'])
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 파생 변수 생성2: 공간(위치) 정보 생성
도시 구 동(ex. 대구광역시 중구 대신동) 형태로 이루어진 '시군구' 컬럼으로 부터 '도시', '구', '동'을 분리하여 새로운 컬럼을 생성해준다. 그리고 '시군구' 컬럼은 삭제해준다.
location_pattern = r'(\S+) (\S+) (\S+)'
train_df[['도시', '구', '동']] = train_org['시군구'].str.extract(location_pattern)
train_df = train_df.drop(columns=['시군구'])
test_df[['도시', '구', '동']] = test_org['시군구'].str.extract(location_pattern)
test_df = test_df.drop(columns=['시군구'])
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 파생 변수 추출3: 도로 형태 정보 추출
도로형태1-도로형태2(ex. 단일로-기타) 형태로 이루어진 '도로형태' 컬럼으로 부터 '도로형태1', '도로형태2'로 분리하여 새로운 컬럼을 생성해준다. 그리고 '도로형태' 컬럼은 삭제해준다.
road_pattern = r'(.+) - (.+)'
train_df[['도로형태1', '도로형태2']] = train_org['도로형태'].str.extract(road_pattern)
train_df = train_df.drop(columns=['도로형태'])
test_df[['도로형태1', '도로형태2']] = test_org['도로형태'].str.extract(road_pattern)
test_df = test_df.drop(columns=['도로형태'])
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 파생 변수 생성4: 계절, 공휴일 정보 생성
교통사고가 계절별로 다를 수 있으므로 '월' 컬럼으로 부터 봄, 여름, 가을, 겨울로 나눈 '계절' 컬럼을 생성해준다. 또한, 공휴일에 따라서도 교통사고에 영향이 있을 수 있으므로 '연', '월', '일' 컬럼으로 부터 공휴일 여부를 나타내는 '공휴일' 컬럼을 생성해준다.
def group_season(df):
df.loc[(df['월'] == 3) | (df['월'] == 4) | (df['월'] == 5), '계절'] = '봄'
df.loc[(df['월'] == 6) | (df['월'] == 7) | (df['월'] == 8), '계절'] = '여름'
df.loc[(df['월'] == 9) | (df['월'] == 10) | (df['월'] == 11), '계절'] = '가을'
df.loc[(df['월'] == 12) | (df['월'] == 1) | (df['월'] == 2), '계절'] = '겨울'
return df['계절']
train_df['계절'] = group_season(train_df)
test_df['계절'] = group_season(test_df)holi_weekday = ['2019-01-01', '2019-02-04', '2019-02-05', '2019-02-06', '2019-03-01', '2019-05-05', '2019-05-12', '2019-06-06', '2019-08-15', '2019-09-12', '2019-09-13', '2019-09-14', '2019-10-03', '2019-10-09', '2019-12-25',
'2020-01-01' ,'2020-01-24' ,'2020-01-25', '2020-01-26', '2020-03-01', '2020-04-30', '2020-05-05', '2020-06-06', '2020-08-15', '2020-08-17', '2020-09-30', '2020-10-01', '2020-10-02', '2020-10-03', '2020-10-09', '2020-12-25',
'2021-01-01' ,'2021-02-11' ,'2021-02-12', '2021-02-13', '2021-03-01', '2021-05-05', '2021-05-19', '2021-06-06', '2021-08-15', '2021-09-20', '2021-09-21', '2021-09-22', '2021-10-03', '2021-10-09', '2021-12-25',
'2022-01-01' ,'2022-01-31' ,'2022-02-01', '2022-02-02', '2022-03-01', '2022-05-05', '2022-05-08', '2022-06-06', '2022-08-15', '2022-09-09', '2022-09-10', '2022-09-11', '2022-09-12', '2022-10-03', '2022-10-09', '2020-10-10', '2022-12-25',
'2023-01-01' ,'2023-01-21' ,'2023-01-22', '2023-01-23', '2023-01-24', '2023-03-01']
train_df['날짜'] = pd.to_datetime(train_df[['연', '월', '일']].astype(str).agg('-'.join, axis=1))
train_df['공휴일'] = train_df['날짜'].isin(pd.to_datetime(holi_weekday)).astype(int)
train_df = train_df.drop(columns=['날짜'])
test_df['날짜'] = pd.to_datetime(test_df[['연', '월', '일']].astype(str).agg('-'.join, axis=1))
test_df['공휴일'] = test_df['날짜'].isin(pd.to_datetime(holi_weekday)).astype(int)
test_df = test_df.drop(columns=['날짜'])
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 파생 변수 생성5: 총 사고발생횟수 생성
'도시', '구', '동' 별로 총 사고발생횟수가 모델 예측에 도움이 될 수 있다고 판단하여 value_counts() 함수로 '사고발생횟수' 컬럼을 생성해주었다.
train_total_df = train_df[['도시', '구', '동']].value_counts().reset_index(name='사고발생횟수')
test_tota_df = test_df[['도시', '구', '동']].value_counts().reset_index(name='사고발생횟수')
train_df = pd.merge(train_df, train_total_df, how='left', on=['도시', '구', '동'])
test_df = pd.merge(test_df, test_tota_df, how='left', on=['도시', '구', '동'])
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 파생 변수 생성6: '구' 컬럼 원핫인코딩
총 8개로 카테고리로 나누어진 범주형 변수 '구' 컬럼을 One-Hot Encoding을 통해 8개의 새로운 컬럼을 생성해준다.
여기서 '구' 컬럼을 새로운 컬럼을 생성하지 않고 Target Encoding 방식으로 변환해주는 방법과 비교하기 위해 '구' 컬럼을 삭제하진 않았다.
from sklearn.preprocessing import OneHotEncoder
# train_df와 test_df의 기상상태 및 노면상태 열 선택
train_categorical_data = train_df[['구']]
test_categorical_data = test_df[['구']]
# OneHotEncoder 인스턴스 생성 및 fit_transform 수행
encoder = OneHotEncoder()
train_encoded = encoder.fit_transform(train_categorical_data)
test_encoded = encoder.transform(test_categorical_data)
# OneHotEncoder가 사용한 카테고리 목록을 가져와서 카테고리 이름을 열 이름으로 변환
feature_names = encoder.get_feature_names_out(['구'])
# 밀집 행렬로 변환 (선택 사항)
train_encoded_dense = train_encoded.toarray()
test_encoded_dense = test_encoded.toarray()
train_encoded_df = pd.DataFrame(train_encoded_dense, columns=feature_names, index=train_df.index)
test_encoded_df = pd.DataFrame(test_encoded_dense, columns=feature_names, index=test_df.index)
# # 기존 열 제거
# train_df = train_df.drop(['구'], axis=1)
# test_df = test_df.drop(['구'], axis=1)
# 인코딩된 열 추가
train_df = pd.concat([train_df, train_encoded_df], axis=1)
test_df = pd.concat([test_df, test_encoded_df], axis=1)
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
(이후에 학습을 위해 사용할 변수를 선택하고, 범주형 변수를 수치형 변수로 변환하는 인코딩 과정을 거친다.)
✔️ 대구 보안등 정보 데이터셋 → 보안등개수 생성
외부데이터로 대구에 설치된 보안등에 따라 교통사고가 영향을 받을 수 있으므로 도시 구 동 번지로 이루어진 '소재지번주소' 컬럼으로 부터 '도시', '구', '동', '번지' 컬럼으로 분리하고, '도시', '구', '동' 컬럼으로 부터 보안등 개수를 세어 '보안등개수' 컬럼을 생성해준다. 여기서 설치된 날짜로부터 보안등 개수도 분리하고 싶었지만, 해당 데이터셋의 최신 설치 연도가 2019년도이므로 날짜 컬럼은 이용하지 않고 생성해주었다. (cf. train 데이터셋은 2019~2021년도, test 데이터셋은 2022년도로 이루어져 있음)
light_df = pd.read_csv('data/external_open/대구 보안등 정보.csv', encoding='cp949')
location_pattern = r'(\S+) (\S+) (\S+) (\S+)'
light_df[['도시', '구', '동', '번지']] = light_df['소재지지번주소'].str.extract(location_pattern)
light_df = light_df.groupby(['도시', '구', '동'])['설치개수'].sum().reset_index()
light_df.rename(columns={'설치개수': '보안등개수'}, inplace=True)
light_df.head()
train_df = pd.merge(train_df, light_df, how='left', on=['도시', '구', '동'])
test_df = pd.merge(test_df, light_df, how='left', on=['도시', '구', '동'])
train_df['보안등개수'].fillna(0, inplace=True) # nan을 0으로 변경
test_df['보안등개수'].fillna(0, inplace=True)
train_df['보안등개수'] = train_df['보안등개수'].astype(int) # 데이터타입 정수형으로 변경
test_df['보안등개수'] = test_df['보안등개수'].astype(int)
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 대구 어린이 보호 구역 정보 데이터셋 → 어린이보호구역개수 생성
마찬가지로 외부데이터로 대구 어린이 보호 구역에 따라 교통사고가 영향을 받을 수 있으므로 도시 구 동 번지로 이루어진 '소재지번주소' 컬럼으로 부터 '도시', '구', '동', '번지' 컬럼으로 분리하고, '도시', '구', '동' 컬럼으로 부터 어린이보호구역 개수를 세어 '어린이보호구역개수' 컬럼을 생성해준다.
child_area_df = pd.read_csv('data/external_open/대구 어린이 보호 구역 정보.csv', encoding='cp949')
location_pattern = r'(\S+) (\S+) (\S+) (\S+)'
# child_area_df['어린이보호구역개수'] = 1
child_area_df[['도시', '구', '동', '번지']] = child_area_df['소재지지번주소'].str.extract(location_pattern)
child_area_df = child_area_df[['도시', '구', '동']].value_counts().reset_index(name='어린이보호구역개수')
child_area_df.head()
train_df = pd.merge(train_df, child_area_df, how='left', on=['도시', '구', '동'])
test_df = pd.merge(test_df, child_area_df, how='left', on=['도시', '구', '동'])
train_df['어린이보호구역개수'].fillna(0, inplace=True) # nan을 0으로 변경
test_df['어린이보호구역개수'].fillna(0, inplace=True)
train_df['어린이보호구역개수'] = train_df['어린이보호구역개수'].astype(int) # 데이터타입 정수형으로 변경
test_df['어린이보호구역개수'] = test_df['어린이보호구역개수'].astype(int)
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 대구 주차장 정보 데이터셋 → (급지분류_1, 2, 3), 주차장개수 생성
마찬가지로 외부데이터로 대구 주차장 정보에 따라 교통사고가 영향을 받을 수 있으므로 도시 구 동 번지로 이루어진 '소재지번주소' 컬럼으로 부터 '도시', '구', '동', '번지' 컬럼으로 분리하고, '도시', '구', '동' 컬럼으로 부터 주차장 개수를 세어 '주차장개수' 컬럼을 생성해준다. 여기서 주차장의 3가지로 된 '급지분류'에 따라서도 영향을 받을 수 있으므로 One-Hot Encoding을 통해 3개의 '급지분류_1, 2, 3' 컬럼도 생성해준다.
parking_df = pd.read_csv('data/external_open/대구 주차장 정보.csv', encoding='cp949')
parking_df = pd.get_dummies(parking_df, columns=['급지구분'])
location_pattern = r'(\S+) (\S+) (\S+) (\S+)'
parking_df[['도시', '구', '동', '번지']] = parking_df['소재지지번주소'].str.extract(location_pattern)
parking_df = parking_df.groupby(['도시', '구', '동'])[['급지구분_1', '급지구분_2', '급지구분_3']].sum().reset_index()
parking_df.head()
train_df = pd.merge(train_df, parking_df, how='left', on=['도시', '구', '동'])
test_df = pd.merge(test_df, parking_df, how='left', on=['도시', '구', '동'])
train_df['급지구분_1'].fillna(0, inplace=True) # nan을 0으로 변경
test_df['급지구분_1'].fillna(0, inplace=True)
train_df['급지구분_2'].fillna(0, inplace=True)
test_df['급지구분_2'].fillna(0, inplace=True)
train_df['급지구분_3'].fillna(0, inplace=True)
test_df['급지구분_3'].fillna(0, inplace=True)
train_df['급지구분_1'] = train_df['급지구분_1'].astype(int) # 데이터타입 정수형으로 변경
test_df['급지구분_1'] = test_df['급지구분_1'].astype(int)
train_df['급지구분_2'] = train_df['급지구분_2'].astype(int)
test_df['급지구분_2'] = test_df['급지구분_2'].astype(int)
train_df['급지구분_3'] = train_df['급지구분_3'].astype(int)
test_df['급지구분_3'] = test_df['급지구분_3'].astype(int)
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
parking_df = pd.read_csv('data/external_open/대구 주차장 정보.csv', encoding='cp949')
location_pattern = r'(\S+) (\S+) (\S+) (\S+)'
parking_df[['도시', '구', '동', '번지']] = parking_df['소재지지번주소'].str.extract(location_pattern)
parking_df = parking_df[['도시', '구', '동']].value_counts().reset_index(name='주차장개수')
parking_df.head()
train_df = pd.merge(train_df, parking_df, how='left', on=['도시', '구', '동'])
test_df = pd.merge(test_df, parking_df, how='left', on=['도시', '구', '동'])
train_df['주차장개수'].fillna(0, inplace=True) # nan을 0으로 변경
test_df['주차장개수'].fillna(0, inplace=True)
train_df['주차장개수'] = train_df['주차장개수'].astype(int) # 데이터타입 정수형으로 변경
test_df['주차장개수'] = test_df['주차장개수'].astype(int)
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ 대구 CCTV 정보 데이터셋 → CCTV개수 생성
마찬가지로 외부데이터로 대구에 존재하는 CCTV 정보에 따라 교통사고가 영향을 받을 수 있으므로 도시 구 동 번지로 이루어진 '소재지번주소' 컬럼으로 부터 '도시', '구', '동', '번지' 컬럼으로 분리하고, '도시', '구', '동' 컬럼으로 부터 CCTV 개수를 세어 'CCTV개수' 컬럼을 생성해준다.
cctv_df = pd.read_csv('data/external_open/대구 CCTV 정보.csv', encoding='cp949')
location_pattern = r'(\S+) (\S+) (\S+) (\S+)'
cctv_df[['도시', '구', '동', '번지']] = cctv_df['소재지지번주소'].str.extract(location_pattern)
cctv_df = cctv_df[['도시', '구', '동']].value_counts().reset_index(name='CCTV개수')
cctv_df.head()
train_df = pd.merge(train_df, cctv_df, how='left', on=['도시', '구', '동'])
test_df = pd.merge(test_df, cctv_df, how='left', on=['도시', '구', '동'])
train_df['CCTV개수'].fillna(0, inplace=True) # nan을 0으로 변경
test_df['CCTV개수'].fillna(0, inplace=True)
train_df['CCTV개수'] = train_df['CCTV개수'].astype(int) # 데이터타입 정수형으로 변경
test_df['CCTV개수'] = test_df['CCTV개수'].astype(int)
display(f"columns of train_df : {train_df.columns}")
display(f"columns of test_df : {test_df.columns}")
display(train_df.head(1))
display(test_df.head(1))
✔️ train 데이터의 ECLO 분포 살펴보기
- 1부터 74까지 ECLO가 분포되어있다.
- ECLO가 6 이하인 데이터가 현저히 많다.
- ECLO가 40 이상인 데이터를 살펴봐도 날씨나 요일 등 특이한점은 못발견하였다. 다만, 대부분 오후 시간대이고, 사고유형, 노면상태, 도로형태가 비슷해보였던 것 같다.
plt.figure(figsize=(16, 7))
ax = sns.countplot(x='ECLO', data=train_df)
for p in ax.patches:
ax.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 10), textcoords='offset points')
✔️ 각 column별 Train 데이터 ECLO 평균 / Train과 Test 데이터 갯수
모든 컬럼에서 train과 test 데이터의 분포가 비슷하였다.
| Column | Insight |
| 요일 |
|
| 기상상태 |
|
| 노면상태 |
|
| 사고유형 |
|
| 연 |
|
| 월 |
|
| 일 |
|
| 시간 |
|
| 구 |
|
| 동 |
|
| 도로형태1 |
|
| 도로형태2 |
|
| 계절 |
|
| 공휴일 |
|
| 사고발생횟수 |
|
| 보안등개수 |
|
| 어린이보호구역개수 |
|
| 주차장개수 |
|
| CCTV개수 |
|
check_columns = ['요일', '기상상태', '노면상태', '사고유형', '연', '월', '일', '시간', '구', '동', '도로형태1', '도로형태2',
'계절', '공휴일', '사고발생횟수', '보안등개수', '어린이보호구역개수', '주차장개수', 'CCTV개수']
temp_train_df = train_df.copy()
temp_train_df = temp_train_df.drop(['ID'], axis=1)
temp_test_df = test_df.drop(['ID'], axis=1).copy()
# 요일 월~일 순으로 고정시키기
weekday_order = ['월요일', '화요일', '수요일', '목요일', '금요일', '토요일', '일요일']
plt.figure(figsize=(20, 70))
for i, col in enumerate(check_columns):
if col in ['요일']:
temp_train_df = temp_train_df.sort_values(by='요일', key=lambda x: x.astype(pd.CategoricalDtype(categories=weekday_order, ordered=True)))
else:
temp_train_df = temp_train_df.sort_values(col)
plt.subplot(len(check_columns), 3, i*3+1)
plt.title(f'train의 {col}별 ECLO 평균')
ax1 = sns.barplot(data=temp_train_df, x=col, y='ECLO', errorbar=None)
if col in ['도로형태2']:
plt.xticks(rotation=90)
if col in ['요일', '기상상태', '노면상태', '사고유형', '연', '월', '구', '도로형태1', '도로형태2', '계절', '공휴일']:
for p in ax1.patches:
ax1.annotate(f'{round(p.get_height(), 2)}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')
plt.subplot(len(check_columns), 3, i*3+2)
plt.title(f'train의 {col}별 데이터 갯수')
ax2 = sns.countplot(data=temp_train_df, x=col)
if col in ['도로형태2']:
plt.xticks(rotation=90)
if col in ['요일', '기상상태', '노면상태', '사고유형', '연', '월', '구', '도로형태1', '도로형태2', '계절', '공휴일']:
for p in ax2.patches:
ax2.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')
if col in ['요일']:
temp_test_df = temp_test_df.sort_values(by='요일', key=lambda x: x.astype(pd.CategoricalDtype(categories=weekday_order, ordered=True)))
else:
temp_test_df = temp_test_df.sort_values(col)
plt.subplot(len(check_columns), 3, i*3+3)
plt.title(f'test의 {col}별 데이터 갯수')
ax3 = sns.countplot(data=temp_test_df, x=col)
if col in ['도로형태2']:
plt.xticks(rotation=90)
if col in ['요일', '기상상태', '노면상태', '사고유형', '연', '월', '구', '도로형태1', '도로형태2', '계절', '공휴일']:
for p in ax3.patches:
ax3.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')
plt.subplots_adjust(hspace=0.7, wspace=0.3)
✔️ 새벽 시간대는 어두워서 '차대사람' 사고가 자주 나는 걸까?
새벽 시간대에 데이터 수는 적은데 ECLO가 큰 이유가 어두워서 '차대사람' 사고가 많은 건지 가설을 세우고 분석해 보니 '사고유형'과는 큰 연관이 없어 보였다. 오히려 새벽 시간대에 새벽 외 시간대보다 '추돌'과 '신호위반'으로 인한 사고가 자주 발생한 듯 보였다.
time_dawn_df = temp_train_df[(temp_train_df['시간'] >= 0) & (temp_train_df['시간'] <= 5)]
time_dawn_not_df = temp_train_df[(temp_train_df['시간'] >= 6) & (temp_train_df['시간'] <= 23)]
time_check_columns = ['사고유형', '사고유형 - 세부분류', '법규위반']
plt.figure(figsize=(12, 15))
for i, col in enumerate(time_check_columns):
time_dawn_df = time_dawn_df.sort_values(col)
plt.subplot(len(time_check_columns), 2, 2*i+1)
plt.title(f'새벽시간대(0~6시)의 데이터 갯수')
plt.xticks(rotation=90)
ax1 = sns.countplot(data=time_dawn_df, x=col)
for p in ax1.patches:
ax1.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')
time_dawn_not_df = time_dawn_not_df.sort_values(col)
plt.subplot(len(time_check_columns), 2, 2*i+2)
plt.title(f'새벽외 시간대(6~24시)의 데이터 갯수')
plt.xticks(rotation=90)
ax2 = sns.countplot(data=time_dawn_not_df, x=col)
for p in ax2.patches:
ax2.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 5), textcoords='offset points')
plt.subplots_adjust(hspace=0.7, wspace=0.3)
✔️ 각 column별 ECLO의 Boxplot
- 빨간점선 : ECLO 평균
- 각 column별의 세부요소들에 대한 boxplot 그려서 boxplot의 세부요소들(최대값, 분위수 등)이 어디 분포되어있는지 보기
plt.figure(figsize=(16, 80))
avg = round(temp_train_df['ECLO'].mean(), 2)
for i, col in enumerate(check_columns):
plt.subplot(len(check_columns), 1, i+1)
plt.axhline(avg, ls=':', label=f'ECLO Mean Line ({avg})', color='r')
plt.legend()
plt.title(f'{col}에 따른 ECLO의 Boxplot')
sns.boxplot(data=temp_train_df, x=col, y='ECLO')
plt.subplots_adjust(hspace=0.3)
✔️ '사망자/중상자/경상자/부상자수'에 따른 ECLO 평균 분포
ECLO의 계산 요소인 '사망자수', '중상자수', '경상자수', '부상자수'에 따른 ECLO 평균 분포를 살펴보았다.
'사망자'는 최대 2명이고, 오히려 '경상자수'가 최대 22명까지 많다.
plt.figure(figsize=(10, 8))
plt.suptitle('ECLO의 각 계산요소 4개에 대한 ECLO 평균 분포', fontsize=16)
plt.subplot(2, 2, 1)
sns.barplot(x='사망자수', y='ECLO', data=temp_train_df, errorbar=None)
plt.subplot(2, 2, 2)
sns.barplot(x='중상자수', y='ECLO', data=temp_train_df, errorbar=None)
plt.subplot(2, 2, 3)
sns.barplot(x='경상자수', y='ECLO', data=temp_train_df, errorbar=None)
plt.subplot(2, 2, 4)
sns.barplot(x='부상자수', y='ECLO', data=temp_train_df, errorbar=None)
display(temp_train_df.groupby(['사망자수'])['ECLO'].describe())
display(temp_train_df.groupby(['중상자수'])['ECLO'].describe())
display(temp_train_df.groupby(['경상자수'])['ECLO'].describe())
display(temp_train_df.groupby(['부상자수'])['ECLO'].describe())


✔️ '사고유형/법규위반/가해운전자차종/피해운전자차종'에 따른 ECLO 평균
여기서 분석해본 것은 학습 시에 사용되지 않는 컬럼이지만, ECLO와 연관이 있는지 개인적인 궁금증으로 확인하기 위해 진행해보았다.
plt.figure(figsize=(15, 20))
for i, col in enumerate(['사고유형 - 세부분류', '법규위반', '가해운전자 차종', '피해운전자 차종']):
temp_train_df = temp_train_df.sort_values(col)
plt.subplot(4, 2, i*2+1)
plt.title(f'{col}에 따른 ECLO 평균')
plt.xticks(rotation=90)
ax1 = sns.barplot(data=temp_train_df, x=col, y='ECLO', errorbar=None)
for p in ax1.patches:
ax1.annotate(f'{round(p.get_height(), 2)}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 10), textcoords='offset points')
plt.subplot(4, 2, i*2+2)
plt.title(f'{col}에 따른 데이터 갯수')
plt.xticks(rotation=90)
ax2 = sns.countplot(data=temp_train_df, x=col)
for p in ax2.patches:
ax2.annotate(f'{int(p.get_height())}', (p.get_x() + p.get_width() / 2., p.get_height()), ha='center', va='center', xytext=(0, 10), textcoords='offset points')
plt.subplots_adjust(hspace=1, wspace=0.3)
✔️ 상관관계 분석해보기
- ECLO를 구하기 위한 사망자수, 중상자수, 경상자수, 부상자수와 연관관계
- ECLO와 경상자수, 중상자수가 연관관계가 높다.
- ECLO와 부상자수는 음의 관계면서 연관관계가 낮다.
- train에만 있는 세부 컬럼들 간의 연관관계가 높다.
- 외부데이터끼리 연관관계가 많이 형성되어 있다.
from category_encoders.target_encoder import TargetEncoder
categorical_features = list(temp_train_df.dtypes[temp_train_df.dtypes == "object"].index)
temp_train_df_le = temp_train_df.copy()
for i in categorical_features:
# TargetEncoder
le = TargetEncoder(cols=[i])
temp_train_df_le[i] = le.fit_transform(temp_train_df_le[i], temp_train_df_le['ECLO'])
plt.figure(figsize=(20, 20))
temp_train_df_corr = temp_train_df_le.corr()
sns.heatmap(temp_train_df_corr, annot=True, fmt=".2f", vmin=-1, vmax=1, cmap='coolwarm', annot_kws={'size': 8})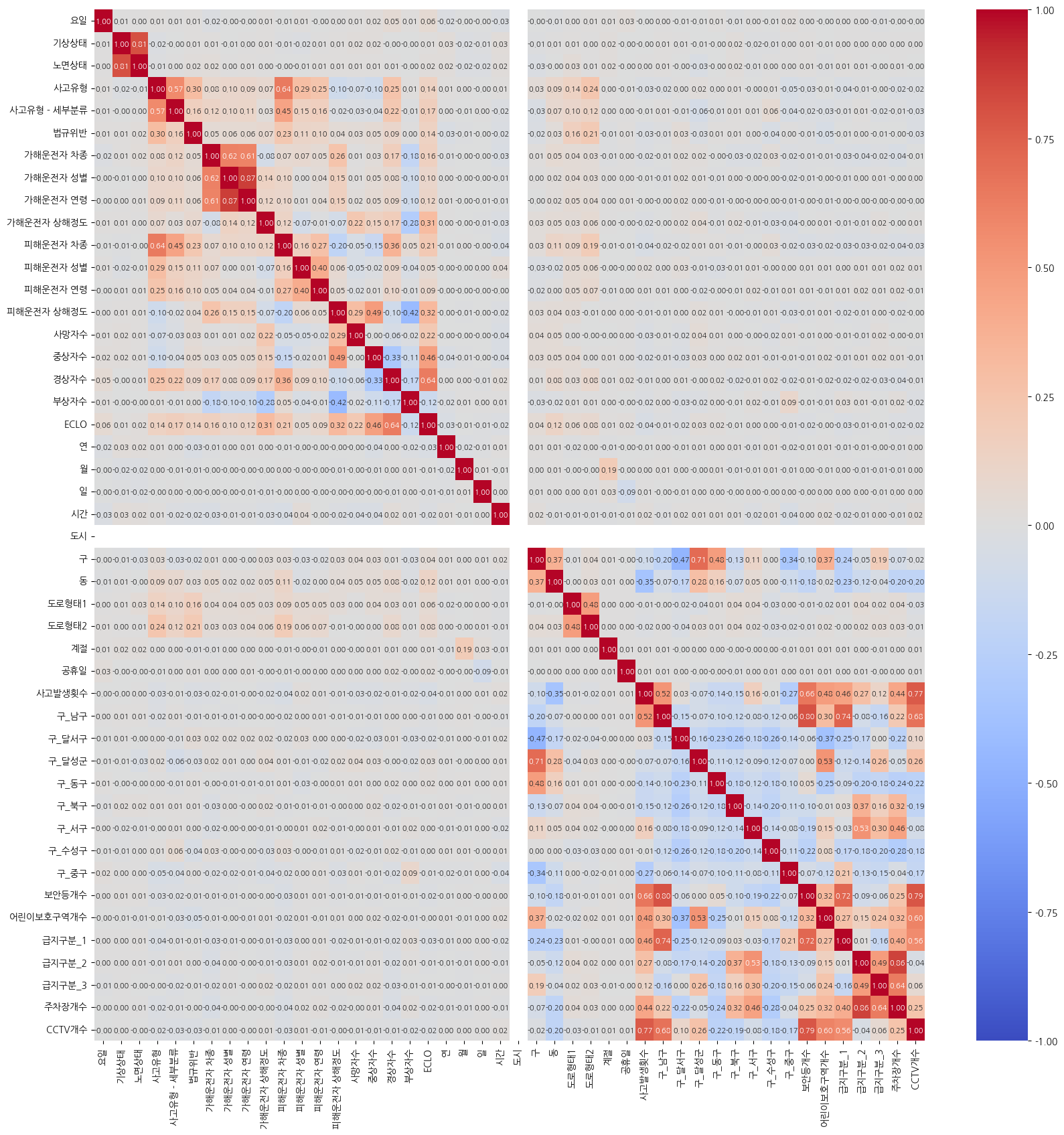
✔️ 다중공선성 확인 - VIF
- VIF가 10 이상인 컬럼을 삭제해보며, 다중공선성이 있는지 확인해보기
- '구'의 One-Hot-Encoding 8개 값은 다른 컬럼을 삭제해도 INF 값이다.
- 주차장 외부데이터에서 파생된 ('급지구분_1', '급지구분_2', '급지구분_3')와 '주차장개수'는 같이 있으면 INF 값이 뜬다.
- '도시'는 1개의 값만 존재하여 VIF 값이 항상 10보다 크다.
from statsmodels.stats.outliers_influence import variance_inflation_factor
def calculate_vif(dataframe):
vif_data = pd.DataFrame()
vif_data["feature"] = dataframe.columns
vif_data["VIF"] = [variance_inflation_factor(dataframe.values, i) for i in range(dataframe.shape[1])]
vif_data['VIF'] = vif_data['VIF'].apply(lambda x: f"{x:.2f}")
return vif_data
temp_train_df_le_vif = temp_train_df_le[['요일', '기상상태', '노면상태', '사고유형', '연', '월', '일', '시간', '도시', '구', '동',
'도로형태1', '도로형태2', '계절', '공휴일', '사고발생횟수', '보안등개수', '어린이보호구역개수', '주차장개수', 'CCTV개수']].copy()
vif_df = calculate_vif(temp_train_df_le_vif)
print(vif_df)
GitHub - CheonJiEun/Competition: 경진 대회에 참가하여 사용 및 구현했던 코드 기록용
경진 대회에 참가하여 사용 및 구현했던 코드 기록용. Contribute to CheonJiEun/Competition development by creating an account on GitHub.
github.com
'Data Analysis & Viz' 카테고리의 다른 글
| [데이터시각화] relplot, catplot, displot (0) | 2023.12.17 |
|---|---|
| [데이터분석] 온라인 화장품 해외 판매 분석하기 (0) | 2023.10.29 |
| [데이터분석] 건강검진 데이터로 가설 검정하기 (0) | 2023.10.26 |
| [데이터시각화] Jupyter, Colab에서 matplotlib 한글 폰트 설정방법 (0) | 2023.10.15 |
| [데이터분석] 서울 종합병원 분포 확인하기 (0) | 2023.10.12 |


