
코딩하는 해맑은 거북이
[데이터분석] 온라인 화장품 해외 판매 분석하기 본문
본 게시물의 내용은 '[코칭스터디 13기] Data Science 2023 → 파이썬으로 시작하는 데이터 사이언스(박조은)' 강의를 듣고 기존에 사용한 데이터 대신 최신 데이터를 사용해 분석하여 작성하였다.
해당 글은 아래의 내용을 다룬다.
📢 사용 데이터셋 정보
💡 데이터 로드하기
💡 데이터 미리보기
💡 데이터 요약정보 살펴보기
💡 데이터 전처리하기
✔️ drop
✔️ melt
✔️ map & apply
✔️ astype & replace
✔️ !=, &, dropna
💡 데이터 시각화 하기
✔️ lineplot & relplot
✔️ pivot_table & heatmap
✔️ barplot
국가통계포털(KOSIS)의 '지역별/상품군별 온라인쇼핑 해외직접판매액의 2017년 1분기~2022년 4분기 데이터' 사용
KOSIS
kosis.kr
여기서 가설은 아래의 뉴스를 통해 '2019년도에는 2018년도보다 화장품 해외 판매액이 증가했을까? 혹은 꾸준히 성장했을까?'로 세우고 분석을 진행해본다! 더 나아가 2022년도 4분까지 화장품 해외 판매는 어떨지도 확인해보자.
지난해 온라인쇼핑 18% 증가…'온라인 해외 수출'도 급증
지난해 연간 온라인쇼핑 규모가 2018년보다 18% 넘게 증가했습니다. 온라인을 통한 해외 판매 규모도 크게 늘어난 것으로 나타났습니다. 통계청이 5일 발표한 2019년 12월 및 연간 온라인쇼핑 동향
world.kbs.co.kr
shape를 통해 969개의 행과 30개의 열로 이루어진 것을 확인할 수 있다.
df_raw = pd.read_csv("data/지역별_상품군별_온라인쇼핑_해외직접판매액_2017_2022.csv", encoding="cp949")
df_raw.shape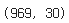
임의로 1개의 데이터를 미리 살펴보자!
* df_raw.head()와 df_raw.tail()을 통해서도 첫 부분과 마지막 부분의 5개의 행씩 살펴볼 수 있다.
df_raw.sample()
df_raw.info()를 통해 컬럼들(Column)과 각 컬럼들의 데이터 타입(Dtype), 메모리 사용량 등을 확인할 수 있다.
이때, Non-null Count가 총 행의 수와 같다면 결측치가 없는 것이고, 그것보다 적다면 결측치가 있는 것으로 볼 수 있다.
* df_raw.columns : 컬럼명만 출력
* df_raw.dtypes : 데이터 타입만 출력
df_raw.info()
"항목", "단위", "Unnamed: 29" 컬럼은 모두 동일한 값 및 유의미하지 않는 값이 들어가 있으므로 지우도록 하자.
df_raw["항목"].unique()
df_raw["단위"].unique()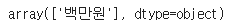
df_raw = df_raw.drop(["항목", "단위", "Unnamed: 29"], axis=1)
df_raw.shape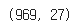
그리고 현재 데이터는 년도/분기가 컬럼에 있으므로, melt로 년도/분기의 열을 행으로 데이터프레임을 재구조화해보자.
id_vars는 유지할 열의 이름, var_name은 새로운 열의 이름, value_name은 원래 데이터프레임의 값이 들어갈 열의 이름을 지정한다.
df = df_raw.melt(id_vars=["지역별", "상품군별", "판매유형별"],
var_name="기간", value_name="백만")
df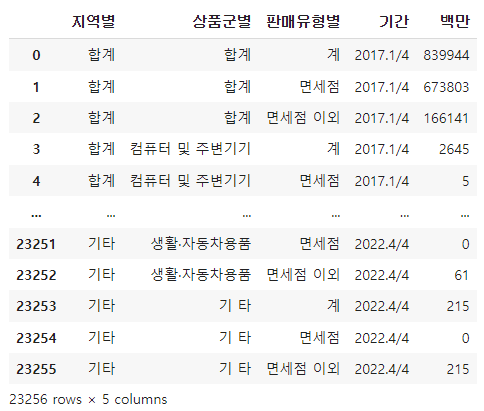
또한, "기간" 컬럼에서 년도/분기가 함께 있으므로 map 함수와 apply 함수를 통해 분리시켜보자.
둘다 각 요소를 변환하거나 매핑할 때 사용하는 것은 똑같지만 큰 차이점은 map은 시리즈에만 적용되고 각 요소에 함수를 적용시킨다. 반면, apply는 데이터프레임 또는 시리즈의 각 열 또는 각 행에 함수를 적용시킬 수 있다.
# 연도 분리하기
df["연도"] = df["기간"].map(lambda x: x.split('.')[0])
df
# 분기 분리하기
df["분기"] = df["기간"].apply(lambda x : x.split('.')[1].split("/")[0])
df
그리고, "분기", "연도", "백만"을 수치 데이터로 표현하기 위해 데이터 타입을 변경시키자.
# 분기와 연도 타입 변경하기
df["분기"] = df["분기"].astype(int)
df["연도"] = df["연도"].astype(int)
df.head()
여기서 "백만" 컬럼에는 문자형인 '-'가 포함되어 수치형으로 변환할 시 에러가 발생하므로, replace 함수로 문자 '-'를 np.nan 값으로 먼저 변경시킨 후 타입을 변경시켜주었다.
df["백만"] = df["백만"].replace("-", np.nan).astype(float)
df.head()
그리고, 합계 데이터는 따로 구할 수 있기 때문에 데이터프레임에서 삭제하자.
여기서는 "!="와 "&' 기호를 통해 합계 데이터가 아닌 데이터프레임을 따로 copy하여 변경해주었다.
df = df[(df["지역별"] != "합계") &
(df["상품군별"] != "합계") &
(df["판매유형별"] != "계")].copy()
df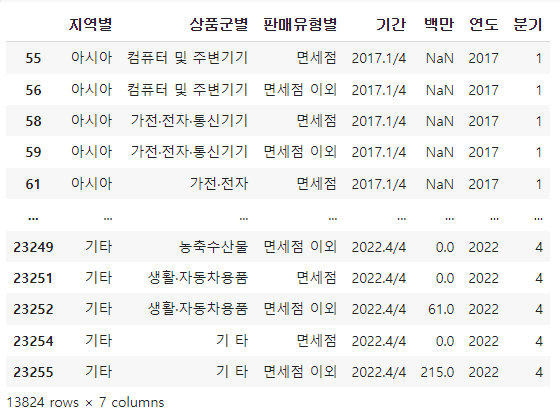
그리고 df.info를 확인해보니 시각화에 주요 컬럼인 "백만"에 결측치가 있는 것을 확인했다.
결측치가 포함된 행 데이터를 지우고 본격적으로 시각화를 시작해보자.
df.info()
df = df.dropna()
df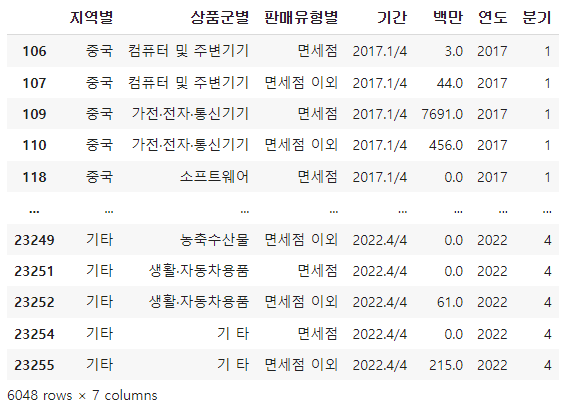
2017년도부터 2022년도까지 각 상품군별에 대해 해외 판매액을 lineplot으로 시각화해보자.
plt.figure(figsize=(15, 4))
sns.lineplot(x="연도", y="백만", data=df, hue="상품군별")
plt.legend(loc='upper right') # 범례 원하는 위치로 설정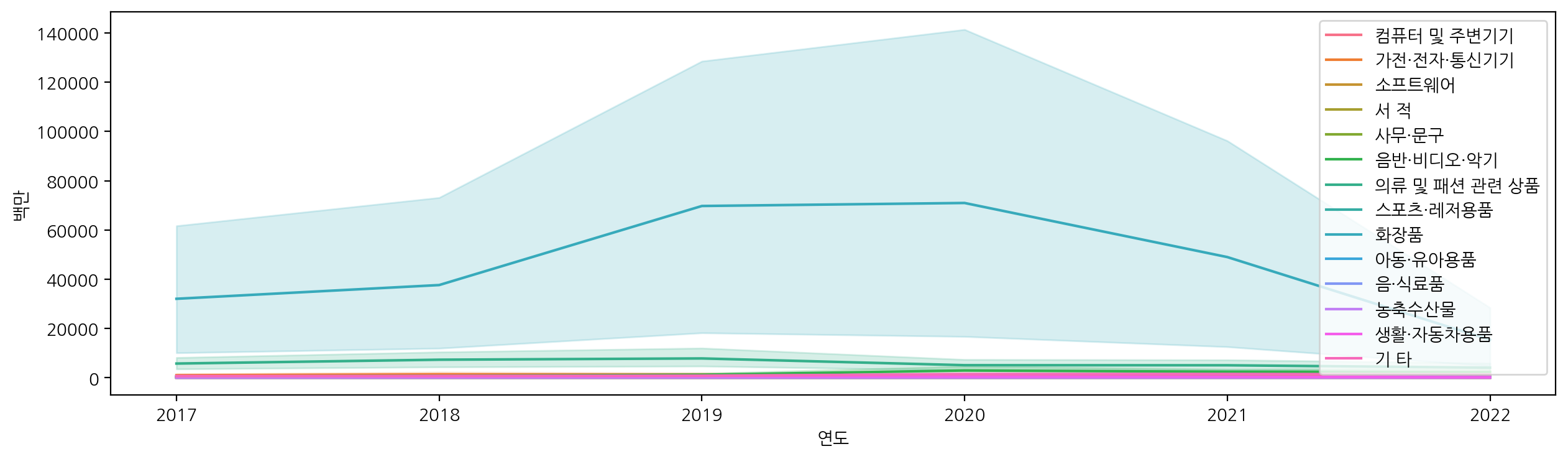
파란색 값이 '화장품'인지 '아동·유아용품' 인지 알아볼 수 없고, 파란색 영역이 너무 커서 다른 상품군별에 대해 식별이 불가능한 상태이다.
relplot은 관계 플롯(relationship plot)을 생성하는데 사용되고, 두 변수 간의 관계를 탐색하고 시각화할 수 있다.
여기서 col 옵션으로도 상품군별을 주어, 각각의 상품군별에 대해 lineplot을 시각화해보자.
sns.relplot(x="연도", y="백만", data=df, hue="상품군별", col="상품군별", col_wrap=4, kind="line")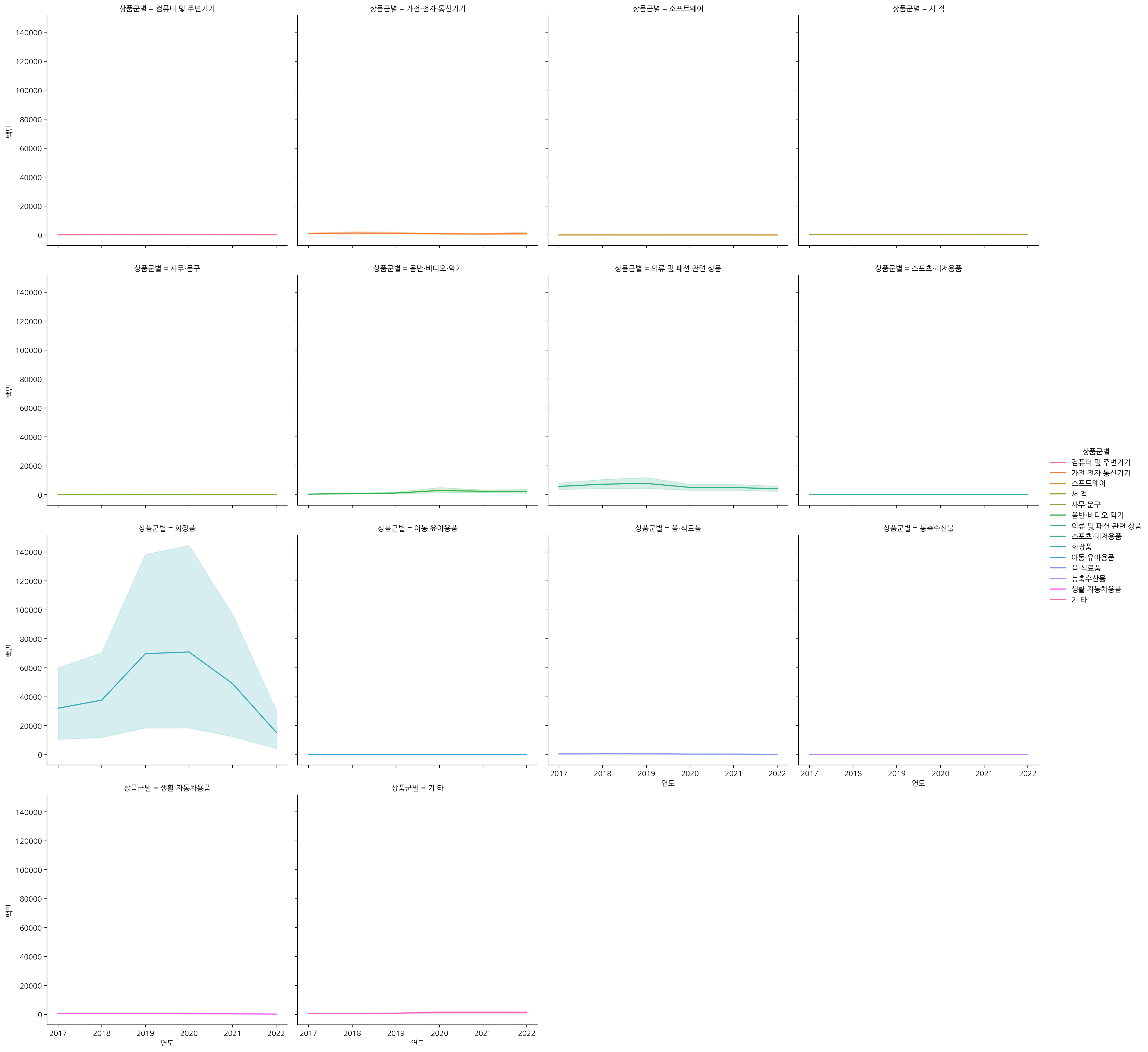
확인해보니 파란색 값이 '화장품'인 것을 확인할 수 있었다.
하지만, 화장품의 판매액이 다른 상품군과의 판매액과 차이가 많이 나서 다른 상품군을 제대로 확인할 수 없으니, 화장품을 제외한 상품군에 대해서 다시 시각화해보자.
df_sub = df[~df["상품군별"].isin(["화장품"])]
df_sub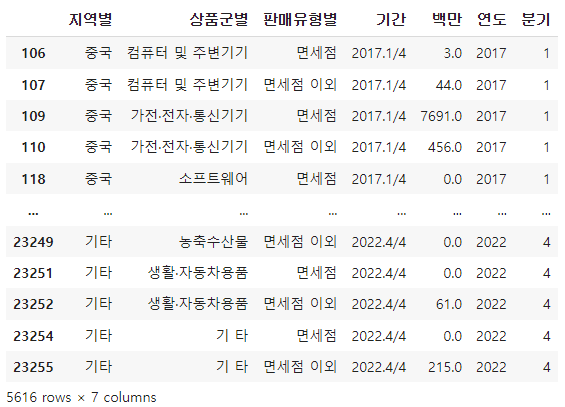
plt.figure(figsize=(15, 4))
sns.lineplot(x="연도", y="백만", data=df_sub, hue="상품군별")
plt.legend(loc='upper right') # 범례 원하는 위치로 설정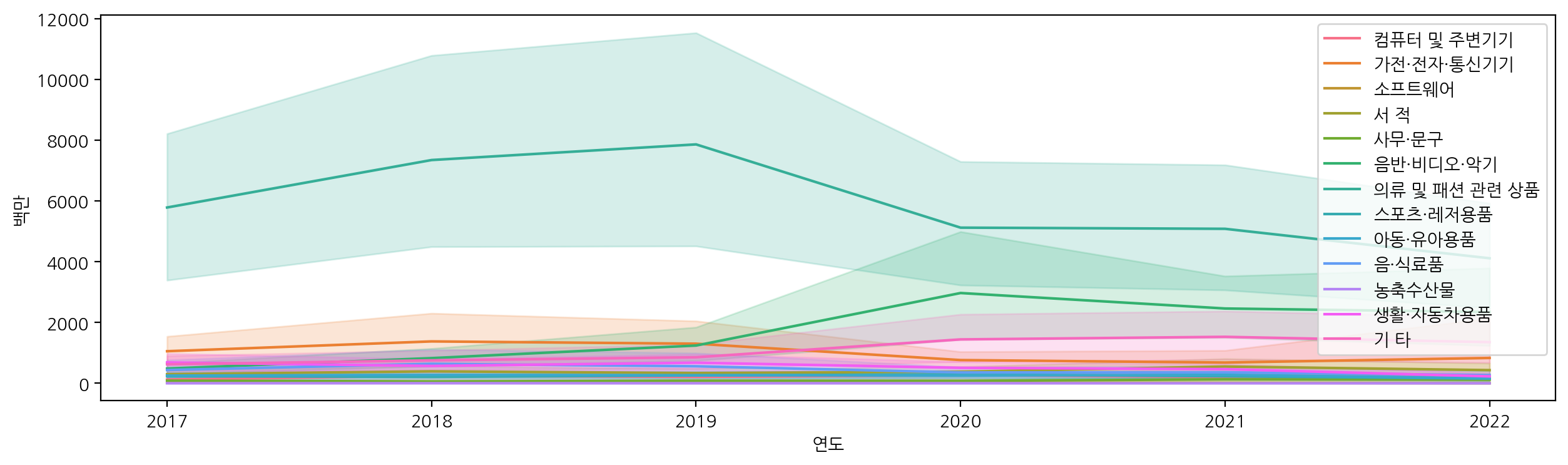
sns.relplot(x="연도", y="백만", data=df_sub,
hue="상품군별", col="상품군별", col_wrap=4, kind="line")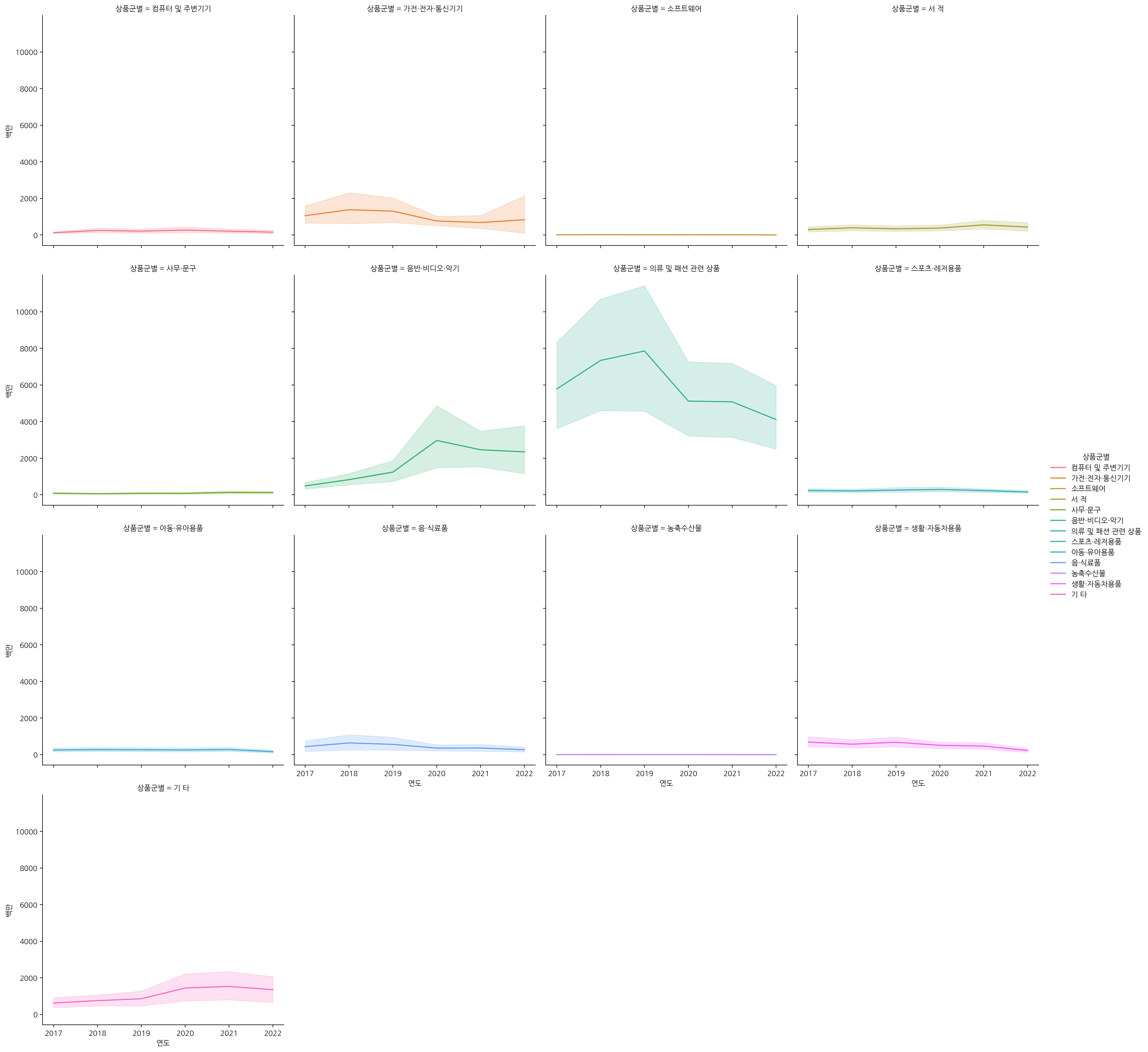
확인해보니, '화장품' 다음으로 '의류 및 패션 관련 상품', '음반·비디오·악기' 순으로 많이 팔린 것을 볼 수 있다.
뉴스에서도 나온 판매 순서가 일치한 것을 검증할 수 있었다..!

그럼 이제 화장품에 대해 연도와 분기별로 살펴보자.
df_cosmetic = df[(df["상품군별"] == "화장품")]
plt.figure(figsize=(15, 4))
sns.lineplot(data=df_cosmetic, x="연도", y="백만", hue="분기")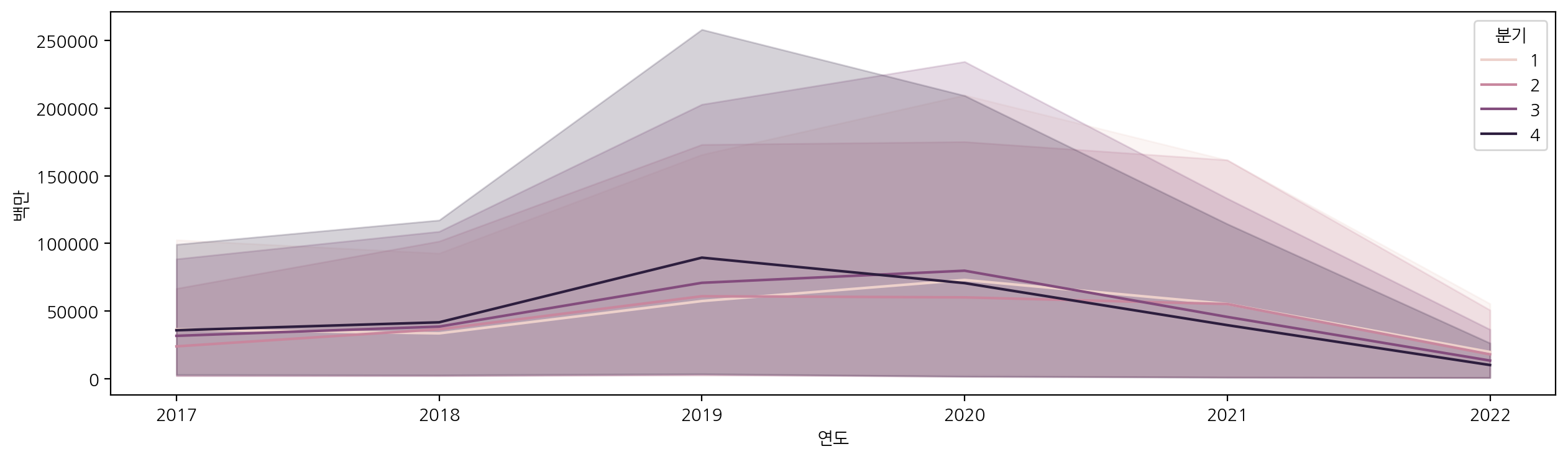
plt.figure(figsize=(15, 4))
plt.xticks(rotation=30)
sns.lineplot(data=df_cosmetic, x="기간", y="백만", hue="지역별")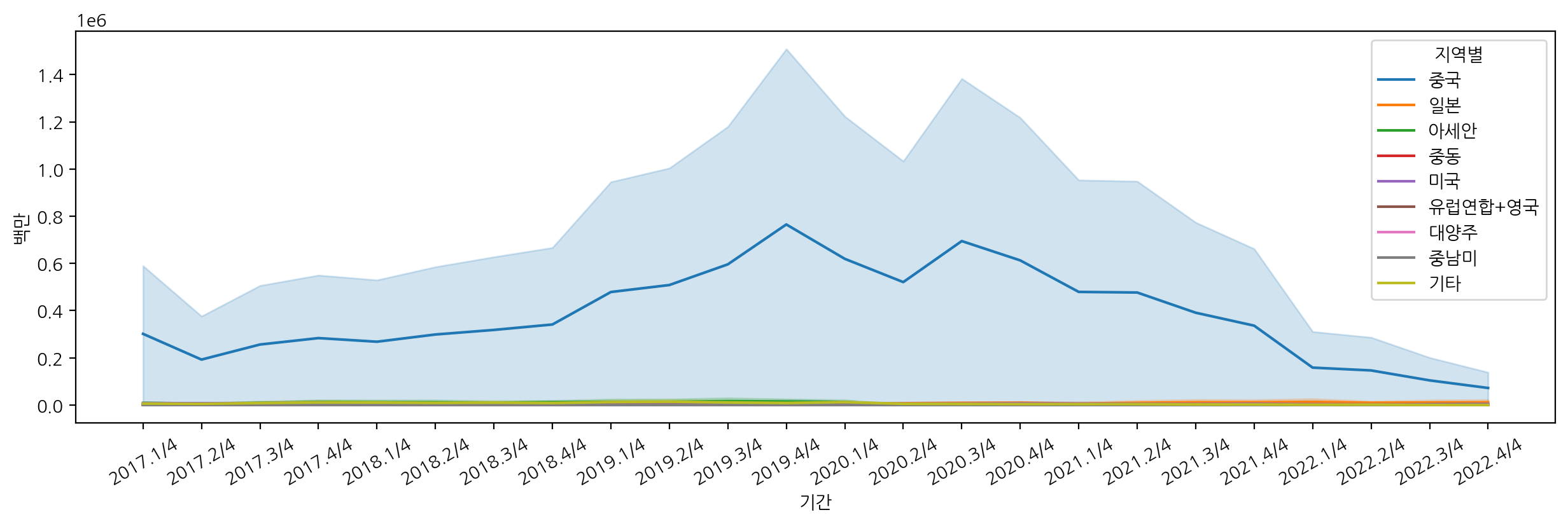
plt.figure(figsize=(15, 4))
plt.xticks(rotation=30)
sns.lineplot(data=df_cosmetic, x="기간", y="백만", hue="판매유형별")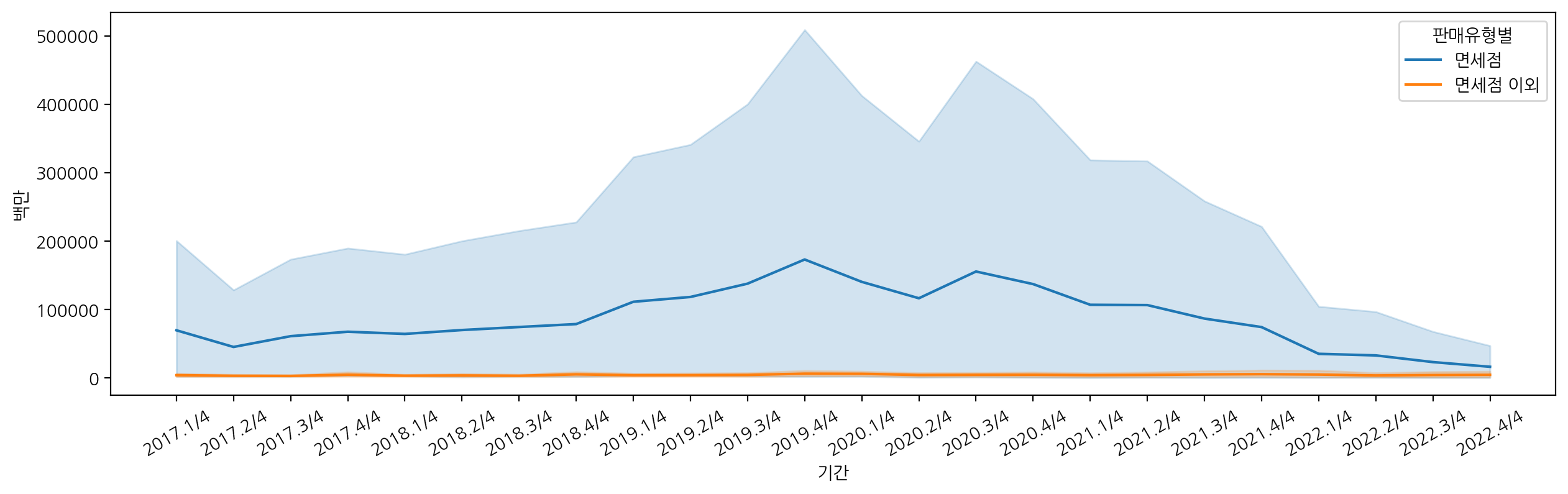
뉴스에서 언급된대로 2019년도에 화장품 판매액이 증가한 것을 볼 수 있고, 이후에 판매액이 점점 떨어진 것을 볼 수 있다.
또한, 중국에서 온라인으로 가장 많이 구입한 것으로 확인할 수 있었다.
추가적으로 의류 및 패션 관련 상품에 대해서도 살펴보자.
df_fashion = df[df["상품군별"].str.contains("의류")]
plt.figure(figsize=(15, 4))
plt.title("의류 및 패션관련 상품")
plt.xticks(rotation=30)
sns.lineplot(data=df_fashion, x="기간", y="백만", hue="지역별")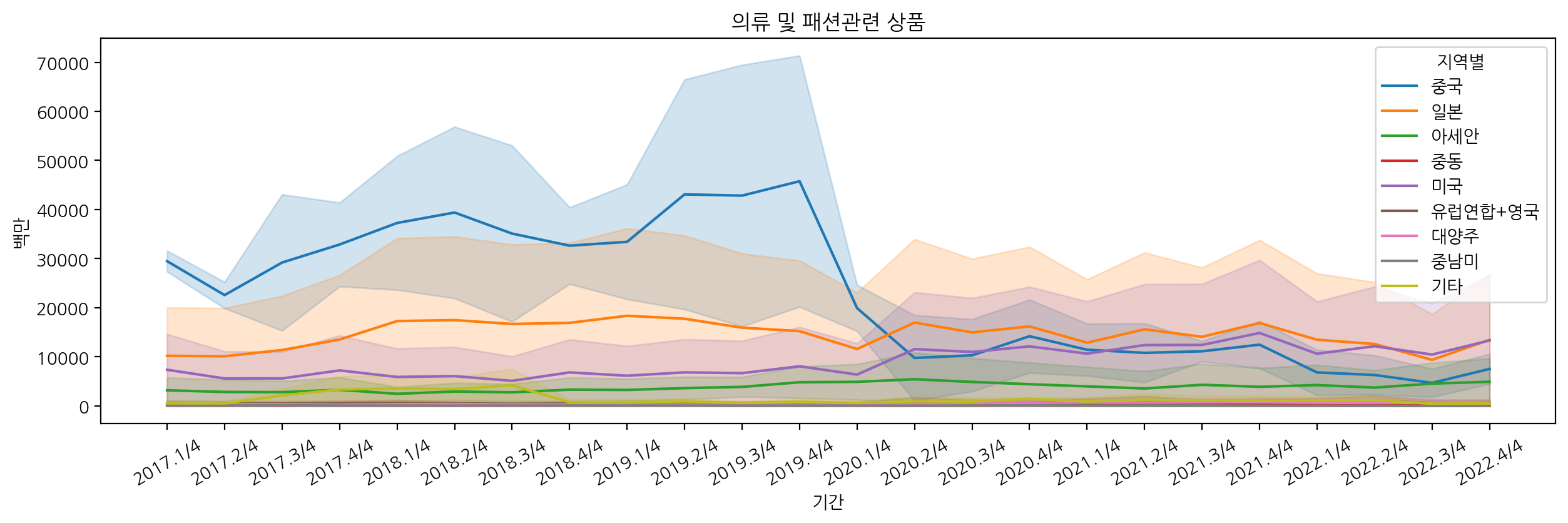
plt.figure(figsize=(15, 4))
plt.xticks(rotation=30)
sns.lineplot(data=df_fashion, x="기간", y="백만", hue="판매유형별")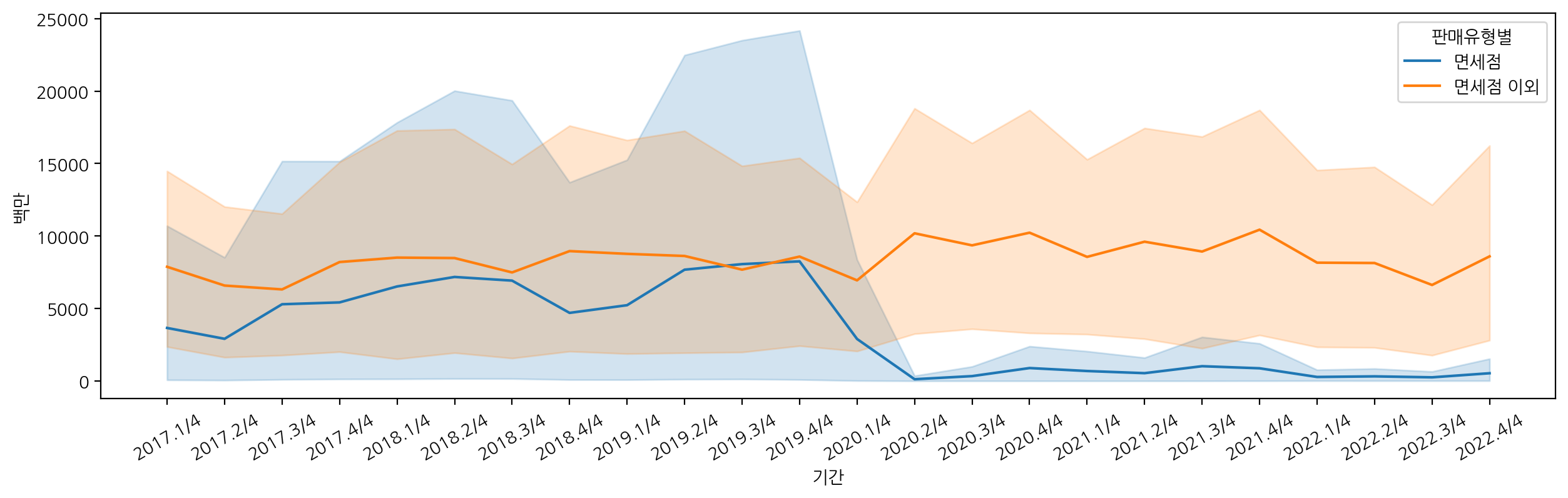
의류 및 패션 관련 상품에 대해 pivot_table로 지역별과 연도로 그룹화하여 집계하고, heatmap으로 시각화해보자.
pivot = df_fashion.pivot_table(index="지역별", values="백만", columns="연도", aggfunc="sum")
pivot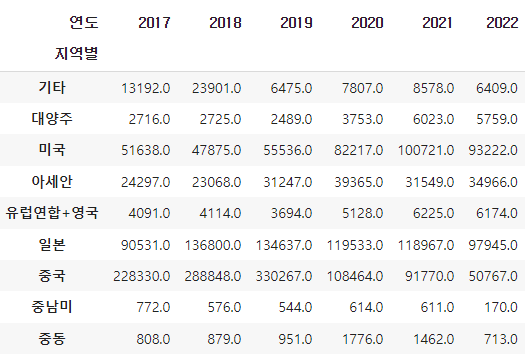
plt.figure(figsize=(15, 7))
sns.heatmap(pivot, cmap="Blues", annot=True, fmt=".0f")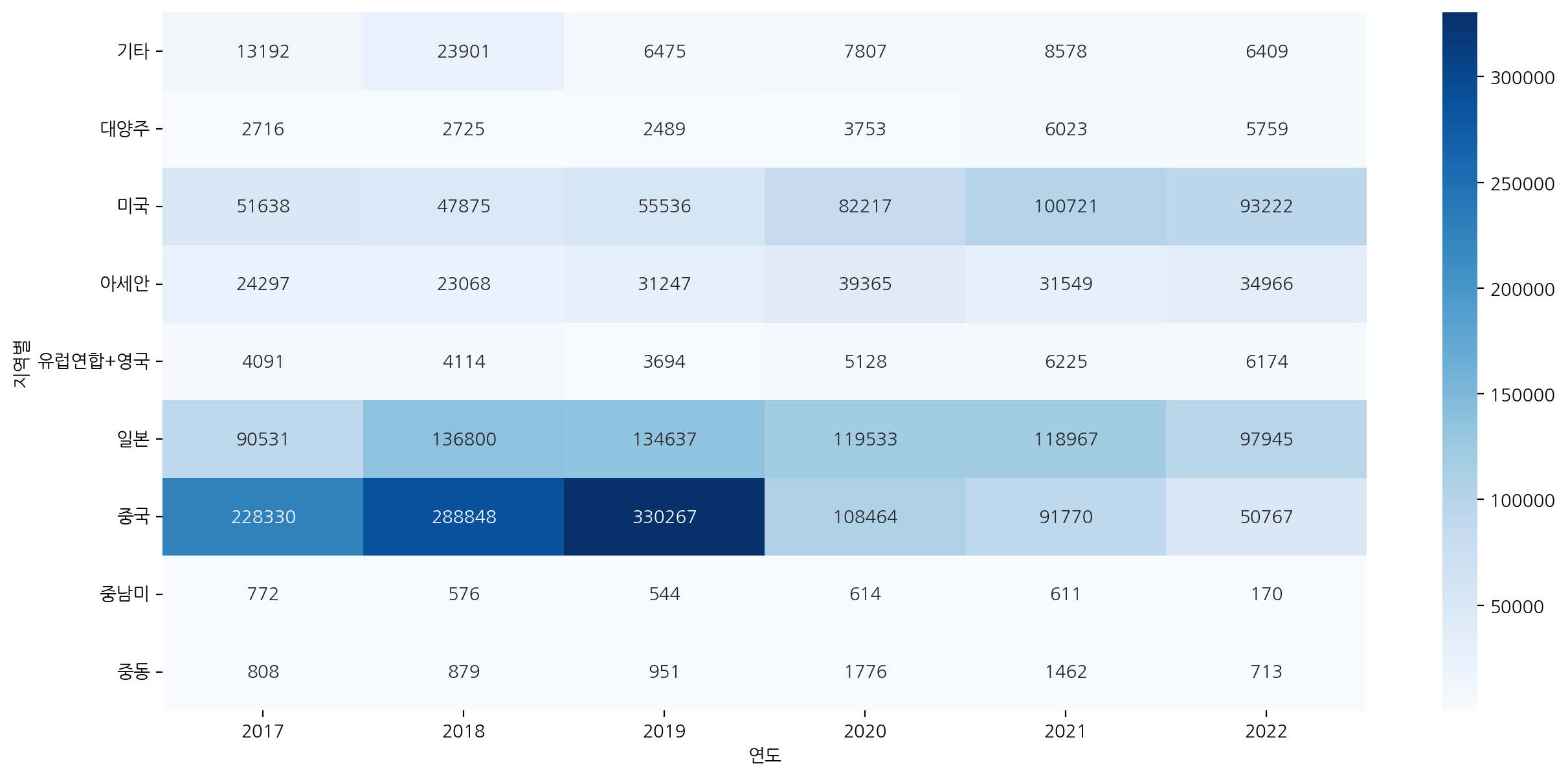
의류 및 패션 관련 상품에 대해서도 중국, 일본, 미국 순으로 가장 많이 구입한 것을 볼 수 있고, 2019년에 해외 판매액이 가장 높은 것으로 확인할 수 있다.
추가적으로 전체 상품군별에 대해서는 온라인 쇼핑 해외 판매액이 증가했는지 확인해보자.
sns.barplot(x="연도", y="백만", data=df_sub, errorbar=None)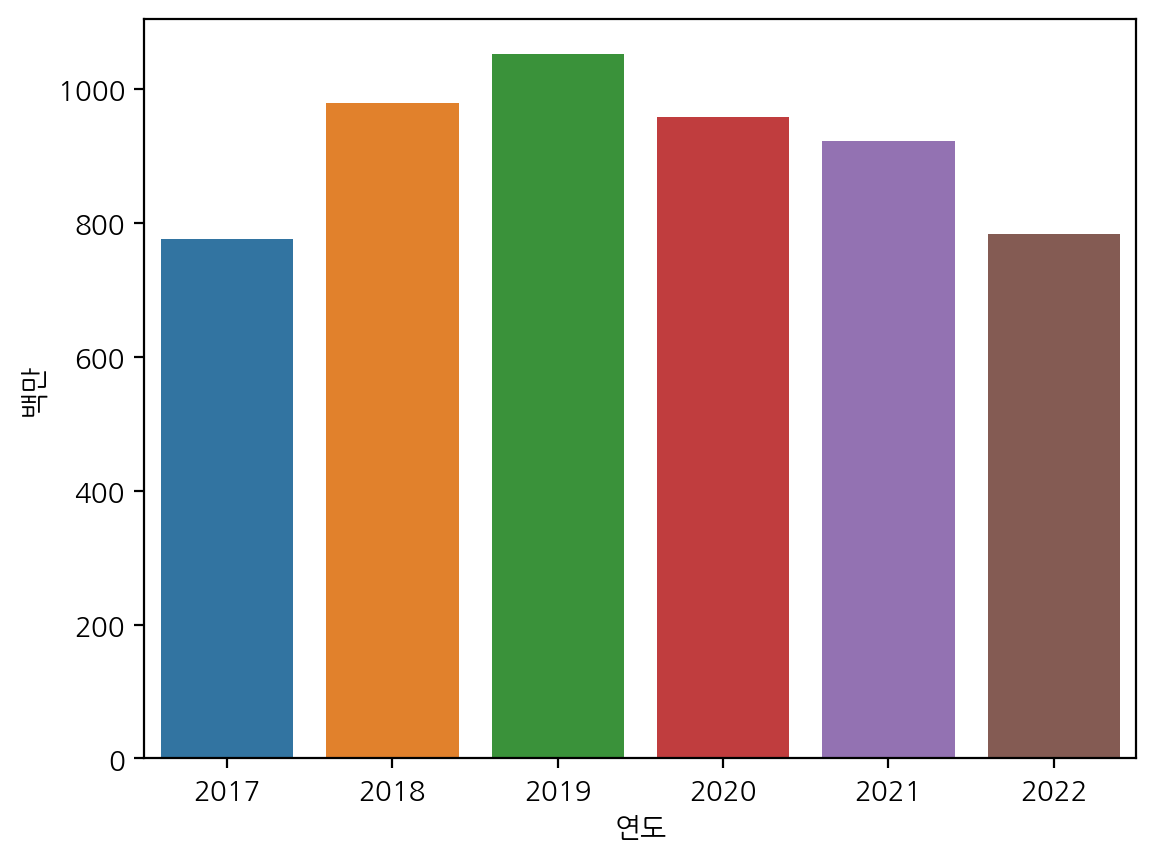
2017~2019년도까지는 판매액이 증가했지만, 2020년도 이후에는 판매액이 감소한 것으로 확인할 수 있다.
(참고) 범례를 그래프 밖에 그리는 방법
Move legend outside figure in seaborn tsplot
I would like to create a time series plot using seaborn.tsplot like in this example from tsplot documentation, but with the legend moved to the right, outside the figure. Based on the lines 339-34...
stackoverflow.com
plt.figure(figsize=(15, 4))
sns.lineplot(x="연도", y="백만", data=df, hue="지역별")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.figure(figsize=(15, 4))
sns.lineplot(x="연도", y="백만", data=df_sub, hue="지역별")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)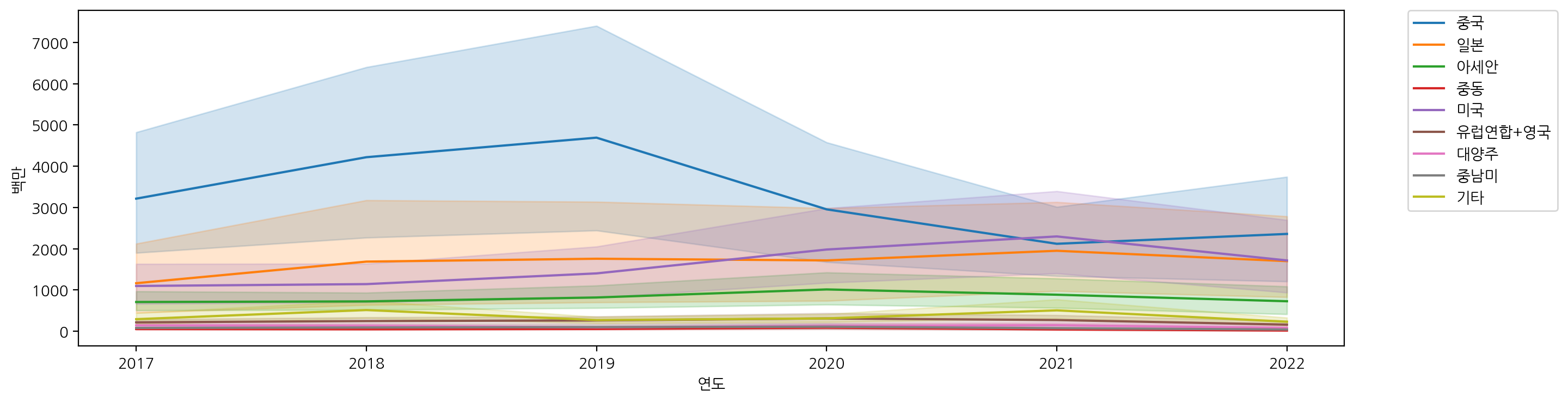
'Data Analysis & Viz' 카테고리의 다른 글
| [데이터시각화] relplot, catplot, displot (0) | 2023.12.17 |
|---|---|
| [데이터분석] 대구 교통사고 데이터 분석하기 (0) | 2023.12.12 |
| [데이터분석] 건강검진 데이터로 가설 검정하기 (0) | 2023.10.26 |
| [데이터시각화] Jupyter, Colab에서 matplotlib 한글 폰트 설정방법 (0) | 2023.10.15 |
| [데이터분석] 서울 종합병원 분포 확인하기 (0) | 2023.10.12 |


