
코딩하는 해맑은 거북이
[데이터분석] 서울 종합병원 분포 확인하기 본문
본 게시물의 내용은 '[코칭스터디 13기] Data Science 2023 → 파이썬으로 시작하는 데이터 사이언스(박조은)' 강의를 듣고 작성하였다.
해당 글은 아래의 내용을 다룬다.
📢 사용 데이터셋 정보
💡 데이터 로드하기
💡 데이터 미리보기
💡 데이터 요약정보 살펴보기
💡 결측치 확인하고 제거하기
💡 기초통계값 확인하기
💡 데이터 색인하기
💡 Folium으로 지도 활용하기
공공데이터 포털의 '소상공인시장진흥공단_상가(상권)정보'의 의료기관만 모여져 있는 '상가(상권)정보_의료기관_201909.csv' 사용
소상공인시장진흥공단_상가(상권)정보_20230930
영업 중인 전국 상가업소 데이터를 제공합니다.<br/>(상호명, 업종코드, 업종명, 지번주소, 도로명주소, 경도, 위도 등)<br/><br/>[데이터 변경 안내] <br/><br/>1. 상권업종분류 : 표준산업분류 기반 업
www.data.go.kr
여기서 가설은 '서울의 종합병원은 고르게 분포되어 있을까?'로 세우고 분석을 진행해본다!
shape를 통해 91335개의 행과 39개의 열로 이루어진 것을 확인할 수 있다.
df = pd.read_csv("data/소상공인시장진흥공단_상가업소정보_의료기관_201909.csv", low_memory=False)
df.shape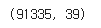
임의로 1개의 데이터를 미리 살펴보자!
* df.head()와 df.tail()을 통해서도 첫 부분과 마지막 부분의 5개의 행씩 살펴볼 수 있다.
df.sample()
df.info()를 통해 컬럼들(Column)과 각 컬럼들의 데이터 타입(Dtype), 메모리 사용량 등을 확인할 수 있다.
이때, Non-null Count가 총 행의 수와 같다면 결측치가 없는 것이고, 그것보다 적다면 결측치가 있는 것으로 볼 수 있다.
* df.columns : 컬럼명만 출력
* df.dtypes : 데이터 타입만 출력
df.info()
df.isnull()은 데이터프레임을 결측치라면 True, 결측치가 아니라면 False로 출력해주는 함수이다.
이때, sum() 함수를 사용하여 결측치의 개수를 확인할 수 있다.
null_count = df.isnull().sum()
null_count
위에서 구한 결측치를 막대그래프로 시각화해보자.
null_count.plot.barh(figsize=(5, 7))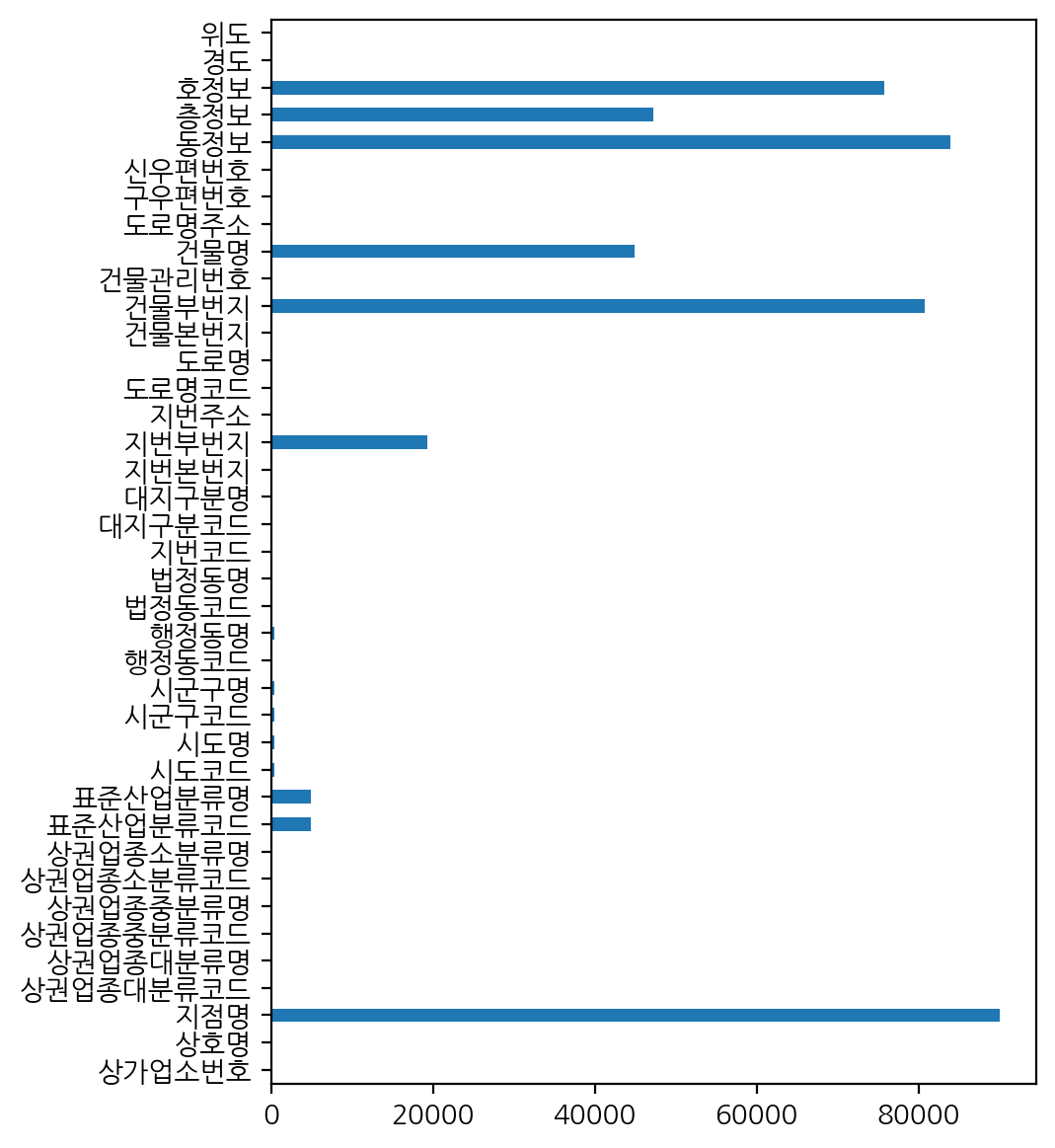
해당 결측치 수를 reset_index를 통해 데이터프레임으로 변경하고, 컬럼명도 지정해주자.
해당 데이터프레임을 sort_values를 통해 결측치가 많은 순으로 정렬하고, head(10)으로 상위 10개만 출력할 수 있다.
df_null_count = null_count.reset_index()
df_null_count.columns = ["컬럼명", "결측치수"]
df_null_count_top = df_null_count.sort_values(by="결측치수", ascending=False).head(10)
df_null_count_top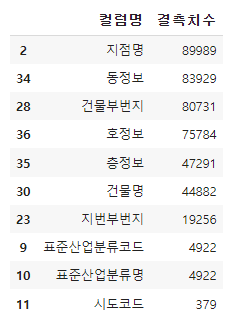
tolist()를 통해 "컬럼명"이라는 컬럼의 값만 가져올 수 있다.
결측치가 많은 상위 10개의 컬럼들을 df.drop을 통해 제거할 수 있다.
drop_columns = df_null_count_top["컬럼명"].tolist()
drop_columns
print(df.shape)
df = df.drop(drop_columns, axis=1)
print(df.shape)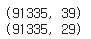
df.info()
"위도" 컬럼의 데이터의 갯수, 평균, 표준편차, 최솟값, 1사분위수, 2사분위수, 3사분위수, 최댓값을 describe를 통해 요약해볼 수 있다.
df["위도"].describe()
2개 이상의 컬럼을 확인할 때는 리스트 형태로 넣어서 확인할 수 있다.
df[["위도", "경도"]].describe()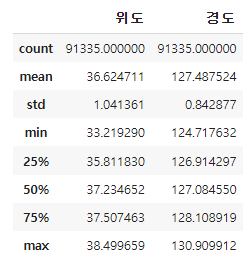
문자형 타입의 컬럼은 df.describe(include="object")를 통해 갯수, 고유한 값의 개수, 각 열에서 자주 발생하는 값, top이 얼마나 자주 나타나는지를 요약해볼 수 있다.
* df.describe(include="number") : 수치형 데이터값 요약할 때
* df.describe(include="all") : 수치형 데이터값, 문자형 데이터값 둘다 요약할 때
df.describe(include="object")
원하는 컬럼에 중복을 제거한 값을 확인하고 싶다면 df["컬럼"].unique()로 확인해보고, nunique()로 갯수를 세어볼 수 있다.
nunique 대신 len을 사용할 수도 있다.
df["상권업종중분류명"].unique()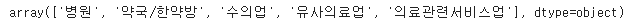
df["상권업종중분류명"].nunique()
# 참고) len으로도 갯수를 셀 수 있음
len(df["상권업종중분류명"].unique())
또한, 원하는 컬럼의 카테고리 형태의 데이터 갯수를 세어보기 위해서 df["컬럼"].value_counts() 로 그룹화하여 확인해볼 수 있다.
city = df["시도명"].value_counts()
city
여기서 normalize=True 옵션을 추가하면, 비율로 구할 수 있다.
city_normalize = df["시도명"].value_counts(normalize=True)
city_normalize
여기서 pandas에 내장된 plot 기능을 바로 사용하여 시각화해 볼 수 있다.
city.plot.barh()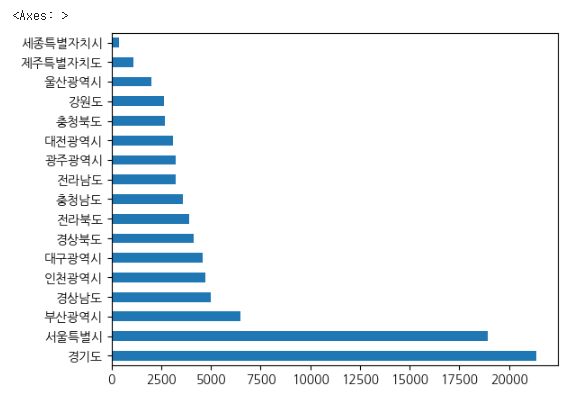
city_normalize.plot.pie(figsize=(7, 7))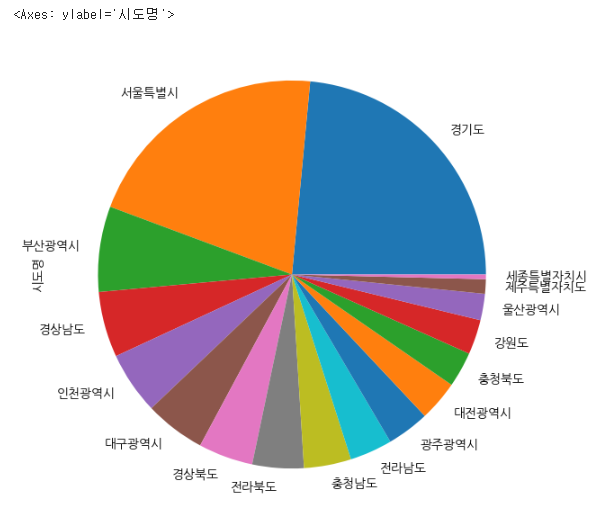
seaborn 라이브러리의 countplot을 사용해서도 같은 결과의 시각화 해볼 수 있다.
import seaborn as sns
sns.countplot(data=df, y="시도명")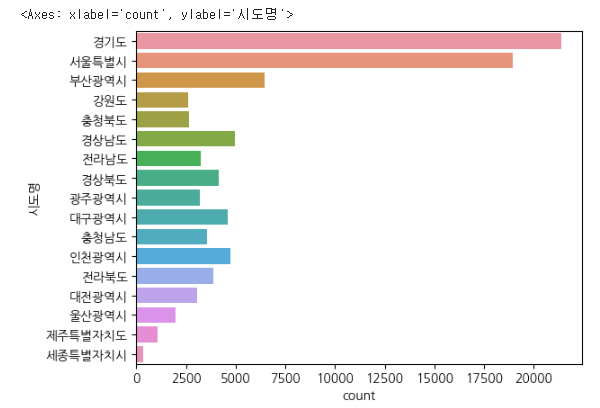
cf) 지금까지의 시각화 결과를 살펴보면, 그래프 위에 <Axes: ~>의 문자가 보일 것이다.
이게 거슬린다면, 시각화 결과를 새로운 변수에 넣어 없앤 상태로 깔끔하게 출력할 수 있다!
c = sns.countplot(data=df, y="시도명")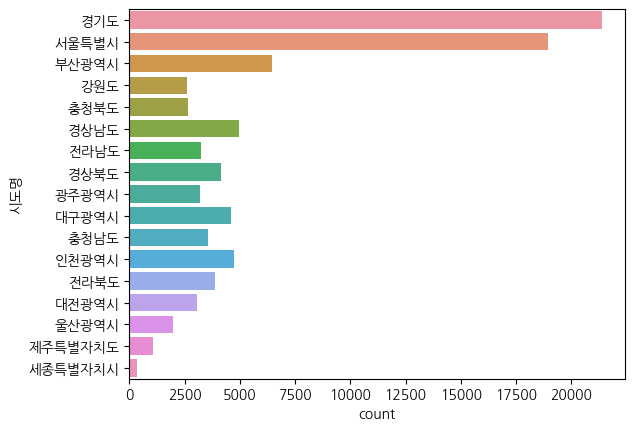
특정 데이터만 가져와서 보고싶을 때는 '==' 기호를 사용해서 특정 조건에 맞는 데이터프레임을 가져올 수 있다.
이때, copy()를 사용하는 이유는 혹여나 새로운 데이터프레임을 변경했을 때, 기존의 데이터프레임이 변경되어버리는 현상을 방지하고자 복사하여 새로운 데이터프레임에 할당하는 것이다.
df_medical = df[df["상권업종중분류명"] == "약국/한약방"].copy()
df_medical.head()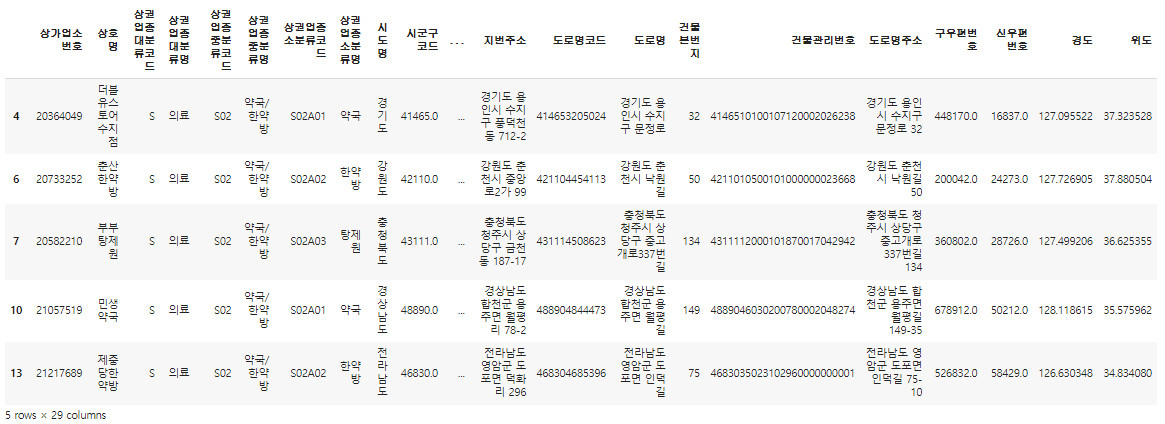
또한, df.loc[행, 열]를 통해 특정 조건에 맞는 혹은 특정 데이터만을 행, 열으로 가져올 수 있다.
m = df["상권업종대분류명"] == "의료"
df.loc[m, ["상권업종중분류명", "상권업종소분류명"]]
# 참고) 아래와 같이 한 줄로도 표현 가능
df.loc[df["상권업종대분류명"] == "의료", ["상권업종중분류명", "상권업종소분류명"]]
여러 조건으로 색인하는 방법은 pandas에서는 and는 &, or은 |, not은 ~를 사용한다.
"상권업종소분류명"이 "종합병원" 인 것과 # "시도명" 이 "서울특별시"인 데이터만 가져오려면 '=='과 '&' 기호를 사용할 수 있다.
df_seoul_hospital = df[(df["상권업종소분류명"] == "종합병원") & (df["시도명"] == "서울특별시")].copy()
df_seoul_hospital
텍스트 데이터에서 특정 문자가 포함된 데이터만 가져오려면, str.contains를 사용할 수 있다.
아래와 같이 "상호명"에 "대학병원"이 들어가는 것을 가져올 수 있다.
df[df["상호명"].str.contains("대학병원")].head(1)
또한, str.startswith를 사용해서 특정 텍스트로 시작하는 데이터, str.endswith을 사용해서 특정 데이터로 끝나는 데이터도 가져올 수 있다.
df[df["도로명주소"].str.startswith("서울")].head(1)
df[df["상호명"].str.endswith("병원")].head(1)
그리고 not 조건을 사용하려면 '~' 기호를 조건 앞에 붙이면 된다.
아래는 "상호명"에 "종합병원"이 포함되어 있지 않은 "상호명"을 가져와보았다.
df_seoul_hospital.loc[~df_seoul_hospital["상호명"].str.contains("종합병원"), "상호명"].unique()
텍스트 데이터에서 or 조건을 주려면, str.contains에서 바로 '|'를 사용할 수 있다.
drop_row = df_seoul_hospital[df_seoul_hospital["상호명"].str.contains("꽃배달|의료기|장례식장|상담소|어린이집")].index
drop_row = drop_row.tolist()
drop_row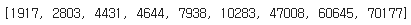
더 나아가서 "시도명"이 "서울특별시"인 데이터의 경도와 위도를 활용해서 시각화를 해보자.
df_seoul = df[df["시도명"] == "서울특별시"].copy()
df_seoul.shape
plt.figure(figsize=(15, 6))
sns.countplot(data=df_seoul, x="시군구명")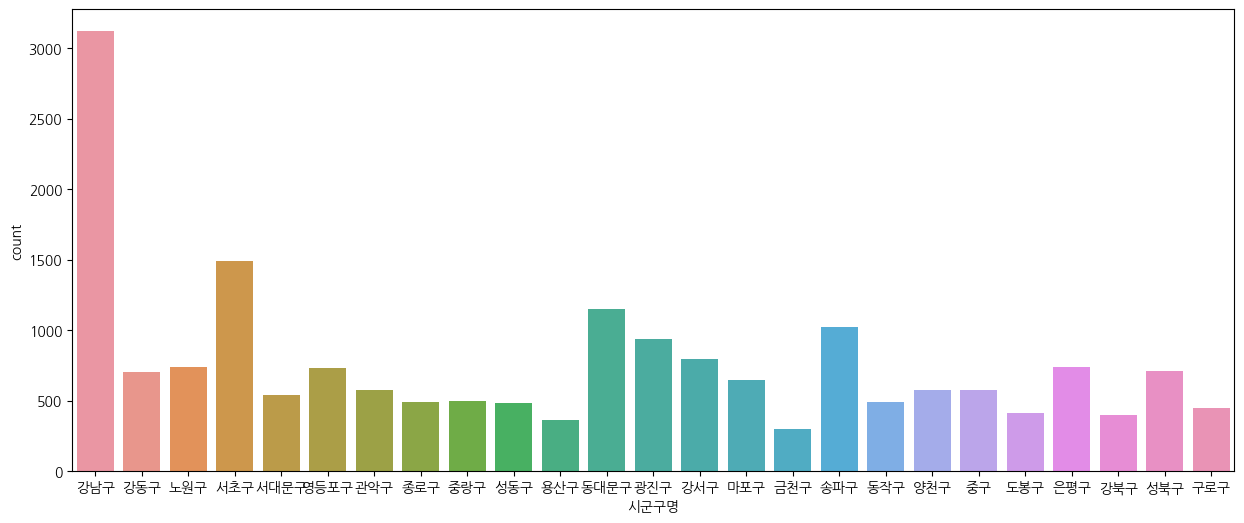
pandas의 plot.scatter를 통해 경도와 위도의 좌표를 찍어볼 수 있다.
df_seoul[["경도", "위도", "시군구명"]].plot.scatter(x="경도", y="위도", figsize=(8, 7), grid=True)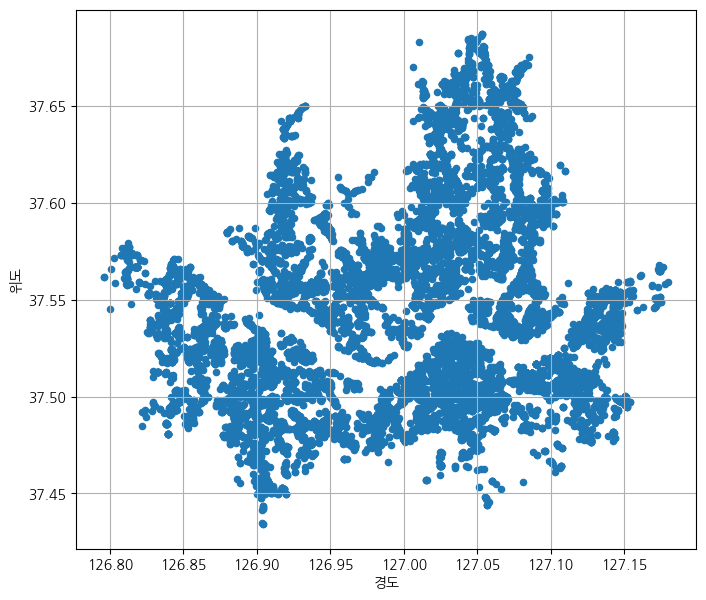
또한, seaborn의 scatterplot을 통해서도 비슷한 결과를 만들어낼 수 있다.
여기서 hue 옵션을 추가해주어 특정 컬럼대로 색깔을 다르게 표시할 수 있다.
plt.figure(figsize=(16, 12))
sns.scatterplot(data=df_seoul, x="경도", y="위도", hue="시군구명") # hue:시군구명 대로 색깔 다르게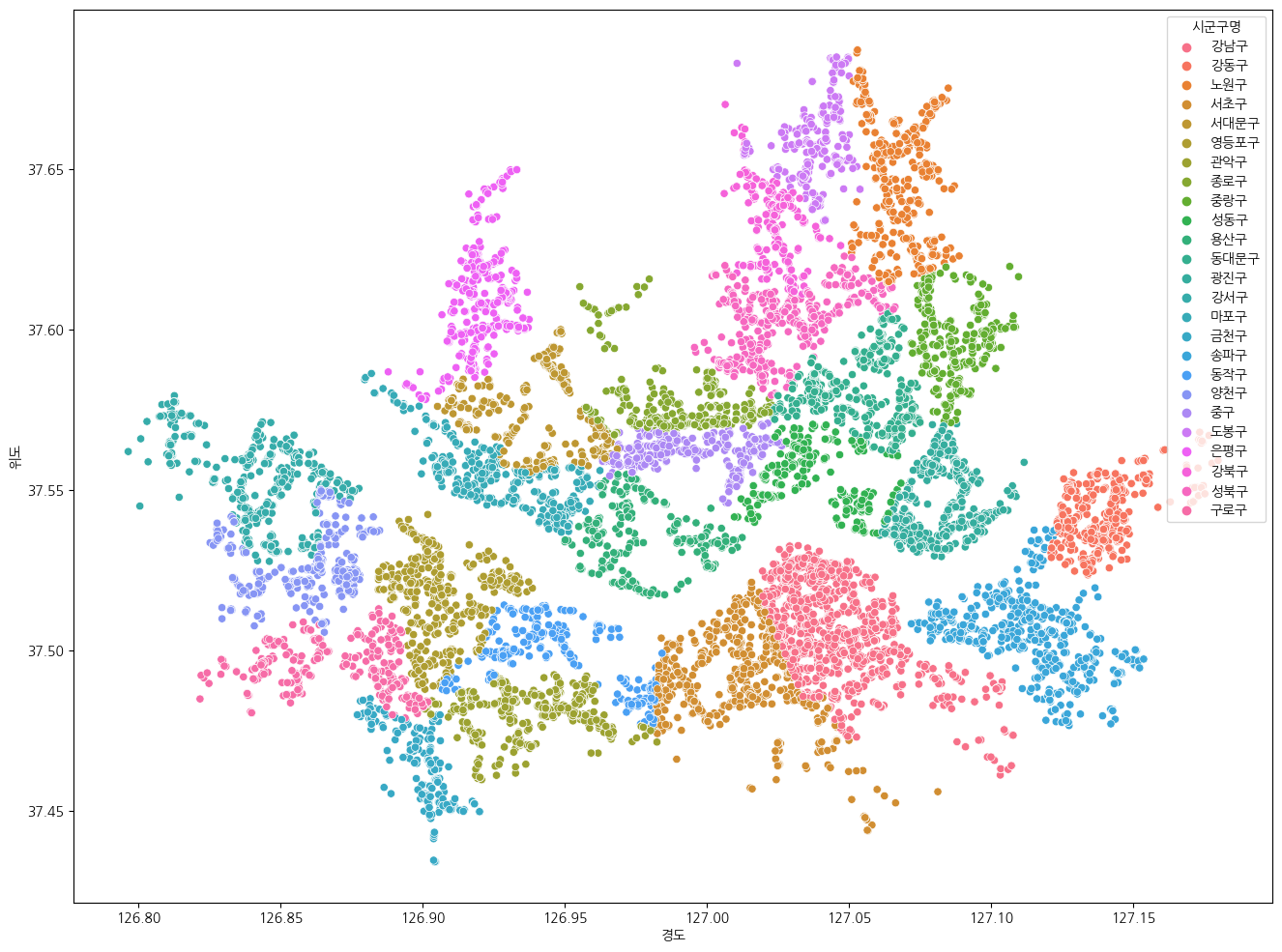
plt.figure(figsize=(16, 12))
sns.scatterplot(data=df_seoul, x="경도", y="위도", hue="상권업종중분류명")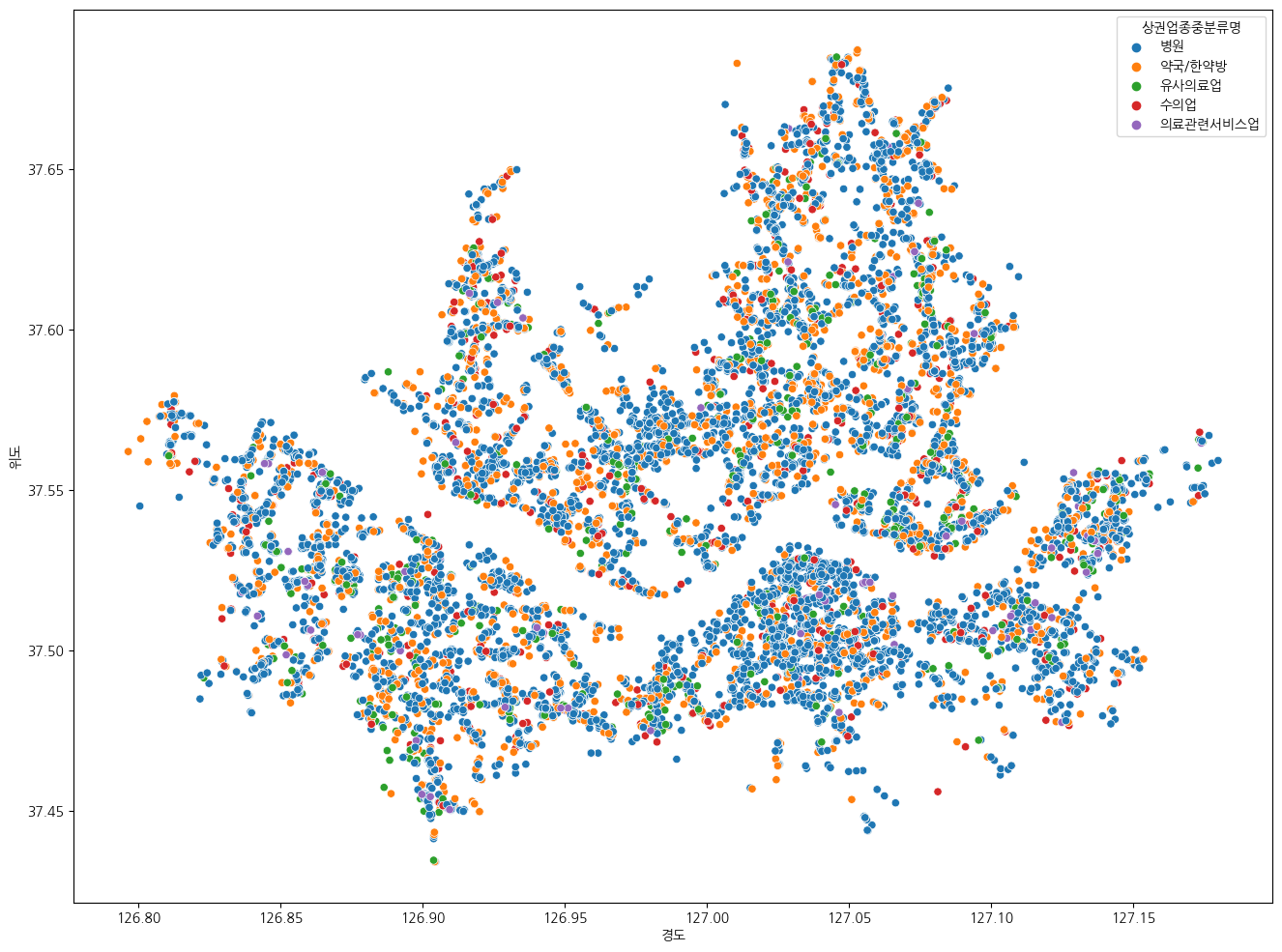
위 결과를 확인해보니, 서울특별시의 지도 형태로 병원이 고르게 분포되어 있는 것을 확인할 수 있었다. (가설검정)
이제 전국 데이터로 "시도명"으로 경도와 위도를 표시해보자.
plt.figure(figsize=(16, 12))
sns.scatterplot(data=df, x="경도", y="위도", hue="시도명")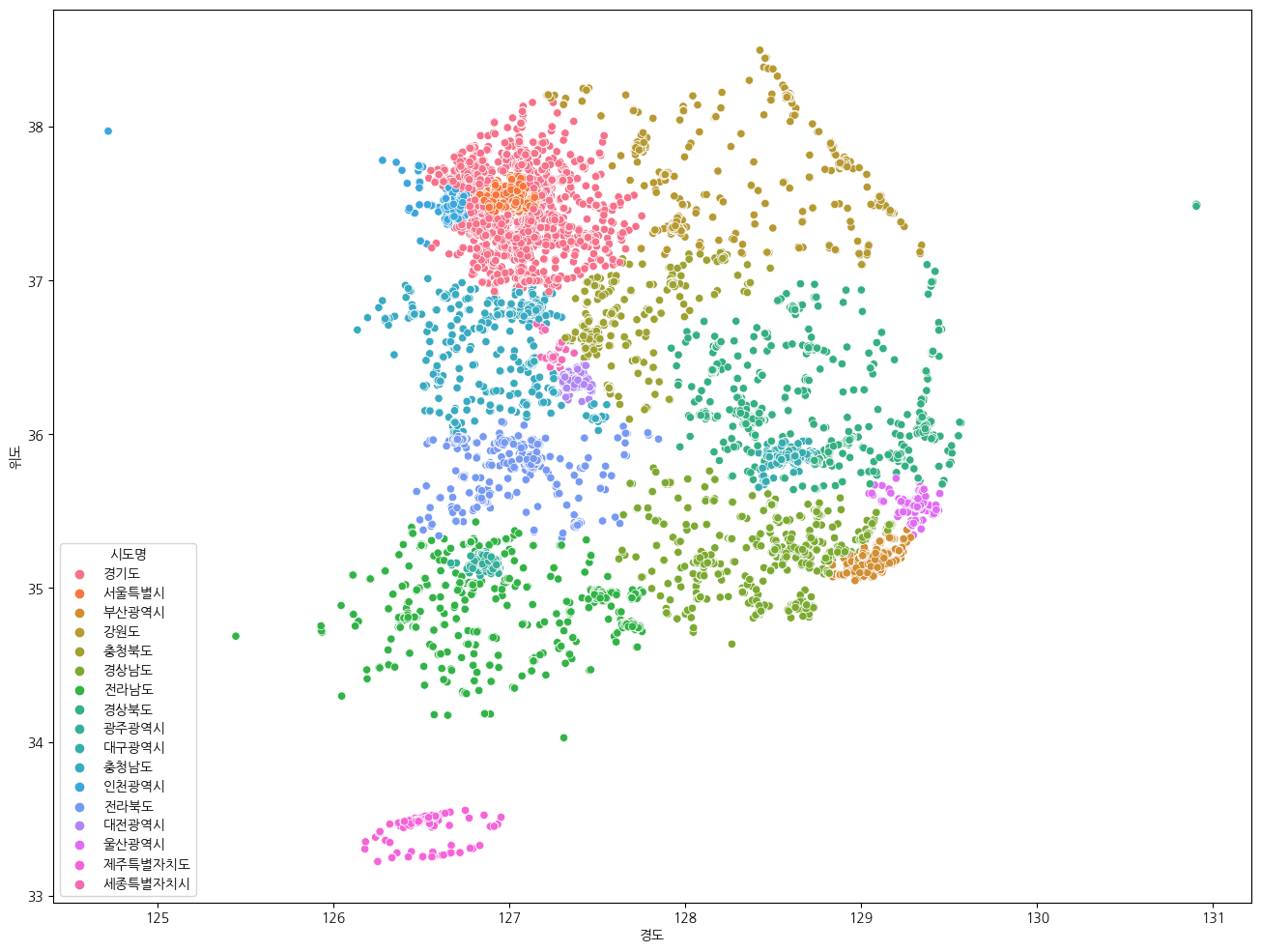
Folium 라이브러리를 따로 설치하여 동적으로 시각화할 수 있는 지도를 활용할 수도 있다.
먼저 라이브러리를 설치하고 선언해준다.
# conda install -c conda-forge folium
import folium
다음에는 지도를 띄울 중심좌표인 location을 구해준다.
여기서는 "서울특별시" 데이터의 위도와 경도의 평균으로 중심을 구해줄 수 있다.
a = df_seoul_hospital["위도"].mean()
b = df_seoul_hospital["경도"].mean()
다음으로 folium.Map 함수를 통해 지도 중심좌표 location과 얼만큼 확대한 상태에서 띄울지 zoom_start를 옵션으로 설정해주고 출력해보자.
m = folium.Map(location=[a, b], zoom_start=12)
m
이제 각 병원의 위치를 아래의 코드로 folium.Marker를 통해 추가해줄 수 있다.
각 마커를 클릭하면 팝업창을 띄우도록 설정도 가능하다.
for n in df_seoul_hospital.index:
name = df_seoul_hospital.loc[n, "상호명"]
address = df_seoul_hospital.loc[n, "도로명주소"]
popup = f"{name}-{address}"
location = [df_seoul_hospital.loc[n, "위도"], df_seoul_hospital.loc[n, "경도"]]
folium.Marker(location=location,
popup=popup).add_to(m)
m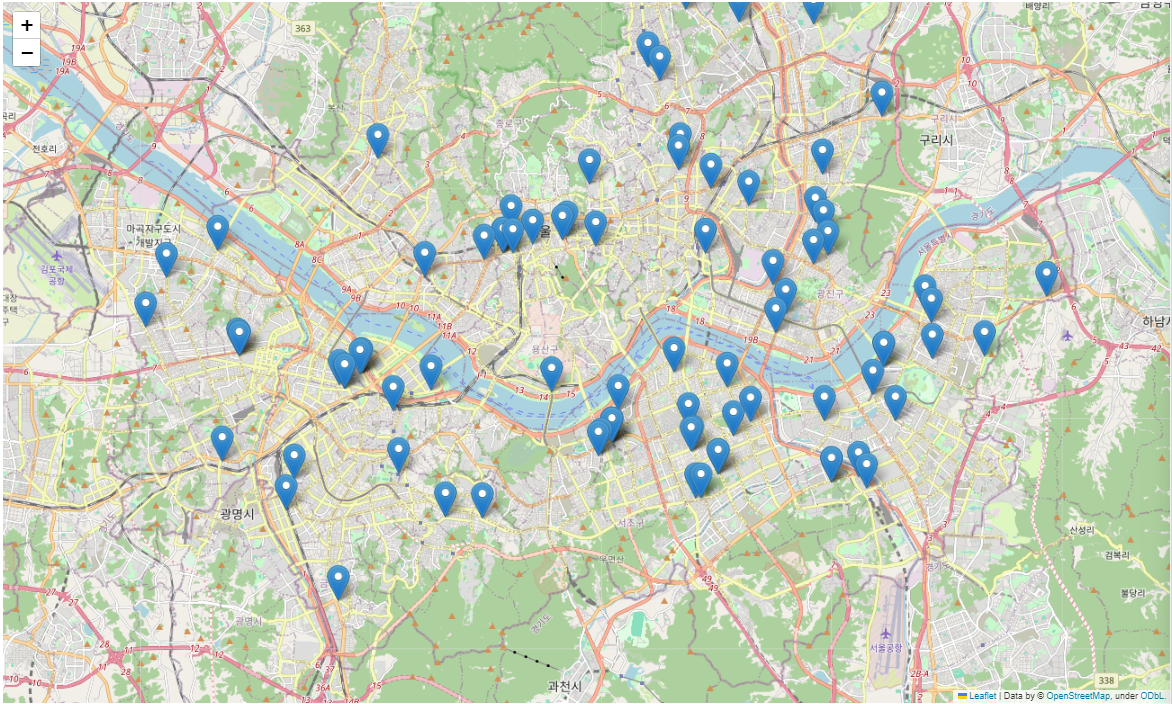
Folium 사용예제)
Getting started — Folium 0.1.dev1+g1d672ab documentation
Make this Notebook Trusted to load map: File -> Trust Notebook
python-visualization.github.io
Jupyter Notebook Viewer
nbviewer.org
'Data Analysis & Viz' 카테고리의 다른 글
| [데이터분석] 건강검진 데이터로 가설 검정하기 (0) | 2023.10.26 |
|---|---|
| [데이터시각화] Jupyter, Colab에서 matplotlib 한글 폰트 설정방법 (0) | 2023.10.15 |
| [데이터분석] 엔트리를 통한 데이터 분석 (0) | 2023.09.01 |
| [데이터시각화] Interactive Visualization (0) | 2023.03.27 |
| [데이터시각화] Missingno, Treemap, Waffle Chart, Venn (0) | 2023.03.27 |


