
코딩하는 해맑은 거북이
인공지능(AI) 기초 다지기 (8) 본문
본 게시물의 내용은 '인공지능(AI) 기초 다지기(부스트코스)' 강의를 듣고 작성하였다.
해당 글은 4-1. Pandas I / 딥러닝 학습방법 이해하기 2가지 파트를 다룬다.
1. Pandas I
2. 딥러닝 학습방법 이해하기
1. Pandas I
pandas
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리, Python계의 엑셀!
- panel data의 줄임말 → pandas
- 고성능 array 계산 라이브러리인 numpy와 통합하여, 강력한 "스프레드시트" 처리 기능을 제공한다.
- 인덱싱, 연산용 함수, 전처리 함수 등을 제공한다.
- 데이터 처리 및 통계 분석을 위해 사용한다.
cf) 테이블 정의 예시
Data table, Sample : 전체 테이블
attribute, field, feature, column : 첫 번째 행
instance, tuple, row : 첫 번째 행이 아닌 의미있는 값을 가진 행
Feature vector : 하나의 feature에 있는 열 값들 (잘안씀)
data : 값, value
pandas 설치 + 주피터 실행하기
conda create -n (가상환경이름) python=3.8 # 가상환경생성
activate (가상환경이름) # 가상환경실행
conda install pandas # pandas 설치jupyter notebook # 주피터 실행하기
데이터 로딩
- 라이브러리 호출
import pandas as pd # 라이브러리 호출- 데이터 url 불러오고 pd.read_csv() 함수를 통해 DataFrame 생성하기
# Data URL
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
# pd.read_csv() : csv 타입 데이터 로드, separate는 빈공간으로 지정하고, Column은 없음
df_data = pd.read_csv(data_url, sep='\s+', header = None)- DataFrame의 처음 5줄 출력하기
괄호 안에 n=??으로 몇 번째 줄까지 출력할 건지 설정 가능
df_data.head() # 처음 다섯줄 출력
- Column Header 이름 지정
# Column Header 이름 지정
df_data.columns = [
'CRIM','ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO' ,'B', 'LSTAT', 'MEDV']
df_data.head()
cf) pandas의 구성
DataFrame : DataTable 전체를 포함하는 Object
Series : DataFrame 중 하나의 Column에 해당하는 데이터의 모음 Object
Series
- Column vector를 표현하는 Object
- numpy.ndarray의 Subclass 이다.
- index 값을 숫자 또는 문자로도 지정가능하다.
- duplicates 가능

- 라이브러리 호출
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
- series 생성
list_data = [1,2,3,4,5]
example_obj = Series(data = list_data)
example_obj
- 리스트로 index 이름을 지정
list_data = [1,2,3,4,5]
list_name = ["a","b","c","d","e"]
example_obj = Series(data = list_data, index=list_name)
example_obj
- 딕셔너리로 data와 index 이름을 지정
Series 함수 - dtype : data type설정 / name : series 이름 설정
dict_data = {"a":1, "b":2, "c":3, "d":4, "e":5}
example_obj = Series(dict_data, dtype=np.float32, name="example_data")
example_obj
- data index에 접근하기
example_obj["a"]
- data index에 값 할당하기 & 타입 변형
example_obj = example_obj.astype(float) # 타입 변형
example_obj["a"] = 3.2
example_obj
- value가 2보다 큰 값 출력하기
cond = example_obj > 2
example_obj[cond]
cf) 이외 연산들
example_obj * 2
np.exp(example_obj) #np.abs , np.log
- series에 특정 index가 있는지 확인
"b" in example_obj
- series를 dict로 변형 : to_dict()
example_obj.to_dict()
- value 리스트 출력
example_obj.values
- index 리스트 출력
example_obj.index
- data에 대한 정보를 저장
(Series).name : series 이름 설정
(Series).index.name : series의 index 이름 설정
example_obj.name = "number"
example_obj.index.name = "alphabet"
example_obj
- index 값을 기준으로 series 생성
dict_data_1 = {"a":1, "b":2, "c":3, "d":4, "e":5}
indexes = ["a","b","c","d","e","f","g","h"]
series_obj_1 = Series(dict_data_1, index=indexes)
series_obj_1
DataFrame
- Series를 모아서 만든 Data Table = 기본 2차원
- DataFrame에 있는 하나의 값을 알기 위해서는 index와 columns를 모두 알아야한다.
- 각각의 값들의 데이터 타입이 다를 수 있다.

- 라이브러리 호출
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
- dict 형태로 저장된 데이터를 columns로 불러 df 생성하기
# Example from - https://chrisalbon.com/python/pandas_map_values_to_values.html
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city'])
df
* 일부 columns 만 불러오기
DataFrame(raw_data, columns = ["age", "city"])
* dict에 없는 key값 불러올 시 NaN으로 저장
DataFrame(raw_data, columns = ["first_name","last_name","age", "city", "debt"])
- series 추출 방법 2가지
df = DataFrame(raw_data, columns = ["first_name","last_name","age", "city", "debt"])
df.first_name # Series 추출 방법1
df["first_name"] # Series 추출 방법2
* 타입 참고!
type(df["first_name"])
- dataframe indexing
* loc : index location
* iloc : index position / index값을 0부터 할당하는 것 처럼 봄
df
df.loc[1]
df["age"].iloc[1:]
df.loc[:3]
df.loc[:, ["first_name", "last_name"]] # 뒤에는 리스트 형태로 넣어줘야함
* loc는 index 이름, iloc은 index number
# Example from - https://stackoverflow.com/questions/31593201/pandas-iloc-vs-ix-vs-loc-explanation
s = pd.Series(np.nan, index=[49,48,47,46,45, 1, 2, 3, 4, 5])
s
s.loc[:3]
s.iloc[:3]
- dataframe handling
* column에 새로운 데이터 할당
df.debt = df.age > 40
df
values = Series(data=["M","F","F"],index=[0,1,3])
values
df["sex"] = values
df
* Transpose
df.T
df.head(3).T
* 값 출력
df.values
* csv 변환 : to_csv()
df.to_csv()
* 일부 column 을 drop한 상태로 출력
df
df.drop("debt", axis=1) # df자체에는 삭제되지 않고, drop만 된 상태로 출력됨
* column 삭제
del df["debt"] # 메모리 주소가 삭제되면서 아예 삭제되는 것.
cf) json파일 형태에서 종종 볼 수 있음 (보통의 경우엔 잘안씀)
# Example from Python for data analyis
pop = {'Nevada': {2001: 2.4, 2002: 2.9}, 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
DataFrame(pop)
selection & drop
- 엑셀 파일 가져오기 & 읽기
여기서는 구글 코랩 드라이브 마운트를 이용하여 엑셀파일을 가져왔다.
from google.colab import drive
drive.mount('/content/drive')import numpy as np
df = pd.read_excel("/content/drive/My Drive/excel-comp-data.xlsx")
df.head()
df.head(2).T # 데이터를 좀더 명확하게 보기위해 transpose를 사용하기도 한다!
- Selection with column names
1) 1개의 column 선택시
df["account"].head(2) # Series
df[["account"]].head(2) # DF
2) 1개 이상의 column 선택시
df[["account", "street", "state"]].head(3)
- Selection with index number
1) column 이름 없이 사용하는 index number는 row 기준 표시
df[:3]
2) column 이름과 함께 row index 사용시, 해당 column만 출력
df["account"][:3]
account_serires = df["account"]
account_serires[:3]
account_serires[[0,1,2]]
account_serires[account_serires<250000] # Boolean index, True인 값만 출력
account_serires[list(range(0, 15, 2))]
- index 변경
df.index = df["account"]
df.head()
del df["account"] # "account" column 삭제
df.head()
- basic, loc, iloc selection
1) Column과 index number
df[["name","street"]][:2]
df[["name", "street"]].iloc[:10]
2) Column과 index name
df.loc[[211829,320563],["name","street"]]
3) Column number와 index number
df.iloc[:2,:2]
- index 재설정
1) index 값 다시 설정
df.index = list(range(0,15)) # reindex
df.head()
2) 기존 index가 사라지고 새로운 index가 생성된 DF 출력, DF 자체는 변경되지않음!
df.reset_index(drop=True) # 기존 index가 사라지고 새로운 index 생성된 DF 출력, DF 자체는 변경X
* DF 자체도 변경하는 방법
여기서 drop을 True로 설정하지 않았으므로, 기존 index는 column으로 추가되었다.
df.reset_index(inplace=True) # inplace=True로 설정해서 DF가 변경됨
df
- data drop
df.drop(index number) : DF 자체는 변경되지 않음!
1) index number로 drop
df.drop(1)
2) 한 개 이상의 index number로 drop
df.drop([0, 1, 2, 3])
3) axis 지정으로 축을 기준으로 drop → column 중에 "city"
df.drop("city",axis=1)
- dataframe의 값을 numpy 형태로 데이터 생성
matrix = df.values
matrix[:3]
matrix[:,-3:]
matrix[:,-3:].sum(axis=1)
df.drop("index", axis=1, inplace=True)
df
matrix = df.values
matrix # numpy 형태로 데이터를 뽑아낼 수 있음
dataframe operations
- series operation
index를 기준으로 연산을 수행한다. 겹치는 index가 없을 경우 NaN 값으로 반환한다.
s1 = Series(range(1,6), index=list("abced"))
s1
s2 = Series(range(5,11), index=list("bcedef"))
s2
s1 + s2
s1.add(s2)
- dataframe operation
dataframe은 column과 index를 모두 고려한다.
add operation을 쓸 때 fill_value를 0으로 설정하면 NaN 값을 0으로 변환하여 계산한다.
mul operation을 쓸 때 fill_value를 1으로 설정하면 NaN 값을 1으로 변환하여 계산한다.
* operation types : add, sub, div, mul
df1 = DataFrame(np.arange(9).reshape(3,3), columns=list("abc"))
df1
df2 = DataFrame(np.arange(16).reshape(4,4), columns=list("abcd"))
df2
df1 + df2
df1.add(df2)
df1.add(df2,fill_value=0)
df1.mul(df2,fill_value=1)
- series + dataframe
기본 연산은 df의 column과 series의 index로 column broadcasting이 일어난다.
row broadcasting 실행하기 위해선 axis를 0으로 두면 된다.
df = DataFrame(np.arange(16).reshape(4,4), columns=list("abcd"))
df
s = Series(np.arange(10,14), index=list("abcd"))
s
df + s
s2 = Series(np.arange(10,14))
s2
df + s2
df.add(s2, axis=0)
lambda, map, apply
- map for series
pandas의 series type의 데이터에도 map 함수 사용가능
function 대신 dict, sequence형 자료 등으로 대체 가능
s1 = Series(np.arange(10))
s1.head(5)
s1.map(lambda x: x**2).head(5)
# f = lambda x: x+5 # lambda function
def f(x):
return x+5
s1.map(f)
z = {1: 'A', 2: 'B', 3: 'C'}
s1.map(z) # dict type으로 데이터 교체, 없는값은 NaN
s2 = Series(np.arange(10,20))
s1.map(s2) # 같은 위치의 데이터를 s2로 전환
* example
df = pd.read_csv("./wages.csv")
df.head()
df.sex.unique() # series data의 유일한 값을 list로 반환함
df["sex_code"] = df.sex.map({"male":0, "female":1}) # 매핑 : 성별 str -> 성별 code
df.head(5)

def change_sex(x):
return 0 if x == "male" else 1
df.sex.map(change_sex).head() # df 자체는 변경X
- replace function
Map 함수의 기능 중 데이터 변환 기능만 담당
데이터 변환시 많이 사용하는 함수
df.sex.replace(
{"male":0, "female":1} # dict type 적용
).head()
df.sex.head(5) # df 자체가 변경되지 않음!
df.sex.replace(
["male", "female"], # target list
[0,1], inplace=True) # conversion list
# df 자체를 바꾸기 위해서는 inplace를 넣어줘야한다! inplace는 데이터 변환결과를 적용
- apply for dataframe
map과 달리 series 전체(column)에 해당 함수를 적용한다.
입력 값이 series 데이터로 입력 받아 handling 가능하다. → 각 column 별로 결과값 반환
내장 연산 함수를 사용할 때도 똑같은 효과를 거둘 수 있다. (mean, std 등)
scalar 값 이외에 series 값의 반환도 가능하다.
df_info = df[["earn", "height","age"]]
df_info.head()
f = lambda x : x.max() - x.min()
df_info.apply(f) # series 데이터로 입력받아 handling 가능
df_info.apply(sum)
df_info.sum()
def f(x):
return Series([x.min(), x.max(), x.mean(), sum(x.isnull())],
index=["min", "max", "mean", "null"])
df_info.apply(f)
- applymap for dataframe
series 단위가 아닌 element 단위로 함수를 적용한다.
series 단위에 apply를 적용시킬 때와 같은 효과
f = lambda x : -x
df_info.applymap(f).head(5) # 모든 값에 적용
f = lambda x: x//2
df_info.applymap(f).head(5)
f = lambda x : -x
df_info["earn"].apply(f).head(5)
pandas built-in functions
df = pd.read_csv("./wages.csv")
df.head()
- describe
Numeric type 데이터의 요약 정보를 보여준다.
df.describe()
- unique
series data의 유일한 값을 list로 반환한다.
unique 함수를 사용해서 라벨 인코딩을 할 수 있다.
df.race.unique()
dict(enumerate(sorted(df["race"].unique())))
# 라벨인코딩1
key = df.race.unique()
value = range(len(df.race.unique()))
df["race"].replace(to_replace=key, value=value) # df자체변경X, inplace 설정해야 변경된다.
# 라벨인코딩2
value = list(map(int, np.array(list(enumerate(df["race"].unique())))[:, 0].tolist()))
key = np.array(list(enumerate(df["race"].unique())), dtype=str)[:, 1].tolist()
value, key
df["race"].replace(to_replace=key, value=value, inplace=True)
df
# 라벨인코딩2 - label str인 sex에 대해서도 index 값으로 변환
value = list(map(int, np.array(list(enumerate(df["sex"].unique())))[:, 0].tolist()))
key = np.array(list(enumerate(df["sex"].unique())), dtype=str)[:, 1].tolist()
value, keydf["sex"].replace(to_replace=key, value=value, inplace=True)
df.head(5)
- sum
기본적인 column 또는 row 값의 연산을 지원한다.
(sub, mean, min, max, count, median, mad, var 등)
df.sum(axis=1)
df.sum(axis=0)
numueric_cols = ["earn", "height", "ed", "age"] # 숫자데이터만 뽑아서 sum
df[numueric_cols].sum(axis=1) # row별 sum
df[numueric_cols].sum(axis=0) # column별 sum
- isnull
column 또는 row 값의 NaN (null) 값의 index를 반환함
df.isnull() # null 인지 아닌지 True or False로 반환
df.isnull().sum() # null인 값의 합
df.isnull().sum() / len(df) # null을 가진 비율
- pd.options.display.max_rows
한번에 보여줄 수 있는 행의 크기를 조절할 수 있다.
pd.options.display.max_rows = 2000 # 한번에 보여줄수있는 행의 크기를 조절할 수 있음
- sort_values
column 값을 기준으로 데이터를 sorting
ascending은 오름차순을 의미한다.
df.sort_values(["age", "earn"], ascending=False).head(10)
df.sort_values("age", ascending=False).head(10)
- cumsum & cummax 등 누적값 구하기
df.cumsum().head(5)
df.cummax().head(10)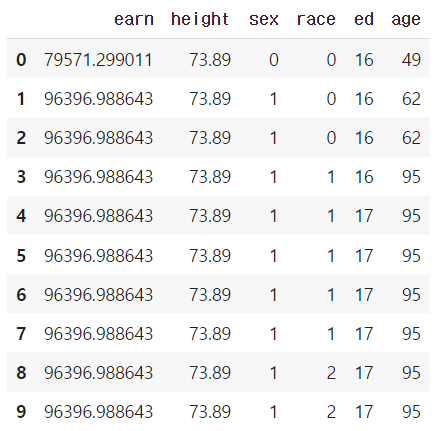
- Correlation & Covariance
상관계수와 공분산을 구하는 함수 (corr, cov, corrwith)
df.age.corr(df.earn)
df.age[(df.age<45) & (df.age>15)].corr(df.earn)
df.age.cov(df.earn)
df.corr() # 모든 column 간에 corr 을 보여줌
df.corrwith(df.earn) # earn 값과 전체 값과의 corr 계산된 걸 보여줌
- value_counts
특정 column의 값의 빈도수를 보여준다.
df.sex.value_counts(sort=True) # 글자의 갯수가 몇개인지
df.sex.value_counts(sort=True) / len(df) # 글자의 갯수에 따른 비율로 보여줌
2. 딥러닝 학습방법 이해하기
선형모델
데이터정답 y와 선형모델의 결과인 \(hat(y)\)의 차이를 L2-Norm 한 기댓값을 최소화하는 것으로 학습한다.
이 방법은 단순한 데이터를 해석할 때는 선형모델이 도움이 되지만,
분류문제나 복잡한 패턴의 문제를 푸는 문제는 선형모델을 가지고 푸는 것이 어렵다.
그래서 비선형모델인 신경망(Neural network)을 고려해봐야한다.
신경망은 비선형모델이긴 하지만, 수식으로 분해해보면 선형모델이 안에 숨어있고 그 선형모델과 비선형함수들의 결합으로 이루어져 있다.
신경망을 배우기 전에 먼저 선형모델에 대해 알아보자.



각 행벡터 \(O_i\)는 데이터 \(X_i\)와 가중치행렬 W 사이의 행렬곱과 절편 b 벡터의 합으로 표현된다고 가정한다.
데이터가 바뀌면 결과값도 바뀌게 된다. 이때 출력벡터의 차원은 d에서 p로 바뀌게 된다.

d개의 변수로 p개의 선형모델을 만들어서 p개의 잠재변수를 설명하는 선형모델을 상상해볼 수 있다.
x1~xd의 변수들이 o1~op까지의 출력으로 이루어지는 도식으로 본다.
화살표는 가중치 행렬 \(W_{ij}\) 이다.
동작방식 : x 변수를 o 변수들 각각에 선형결합해서 연결하게 될때 p개의 모델을 만들어야 한다.
그럼 d개의 x 변수들 각각이 p개의 모델을 가져야 하므로, 화살표의 갯수는 d x p 가 필요하다.
d x p는 가중치행렬의 크기와 같다.
신경망(Neural network) - 비선형모델
주어진 데이터가 특정 클래스에 속하는지 예측하는 문제(분류문제)에서 사용할 수 있다.
분류문제를 풀 때, 학습시키기 위해 softmax 함수가 필요하다.
softmax 함수

소프트맥스(softmax) 함수는 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산이다.
분류 문제를 풀 때 선형모델과 소프트맥스 함수를 결합하여 예측한다.
>> 선형모델의 결과에 소프트맥스 함수를 시키고 이를 통해 특정 벡터가 어떤 클래스에 속할 확률을 계산해준다.

* donumerator에서 np.max(vector) 를 빼준 이유 : 소프트맥스 함수가 지수연산을 사용해서 너무 큰 값이 들어오면 오버플로우가 발생할 수 있기 때문에 이를 방지하고자 함.
그러나 추론을 할 때는원-핫(one-hot) 벡터로 최대값을 가진 주소만 1로 출력하는 연산을 사용해서 softmax를 사용하진 않는다. 학습할 때만 소프트맥스 함수를 사용한다.

신경망은 선형모델과 활성함수(activation function)를 합성한 함수이다.
이러한 트릭을 사용해서 분류문제가 아닌 회귀문제에서 소프트맥스 함수 말고 다른 활성 함수를 사용해서 비선형함수로 모델링할 수 있다.

활성함수
활성함수(activation function)는 R 위에 정의된 비선형(nonlinear)함수로서 딥러닝에서 매우 중요한 개념이다.
활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없다.
시그모이도(sigmoid) 함수나 tanh 함수는 전통적으로 많이 쓰이던 활성함수지만 딥러닝에선 ReLU 함수를 많이 쓰고 있다.


활성함수 σ는 비선형함수로 잠재벡터 Z의 각 노드에 개별적으로 적용하여 새로운 잠재벡터 H를 만든다.
잠재벡터 H에서 가중치행렬 \(W^{(2)}\)와 \(b^{(2)}\)를 통해 다시 한 번 선형변환해서 출력하게 되면 (\(W^{(2)}\), \(W^{(1)}\))를 파라미터로 가진 2층(2-layers) 신경망이다. >> 가중치가 2개 있기 때문.
이를 반복한 것을 다층 (multi-layer) 퍼셉트론(MLP) 이라 부른다.
다층 (multi-layer) 퍼셉트론(MLP)
다층 (multi-layer) 퍼셉트론(MLP)은 신경망이 여러층 합성된 함수이다.

σ(Z)는 (σ(\(Z_1\), ... , σ(\(Z_n\))으로 이루어진 행렬이다.
MLP 패러미터는 L개의 가중치 행렬 \(W^{(L)}\), ... , \(W^{(1)}\)로 이루어져 있다.
ℓ = 1, ... , L까지 순차적인 신경망 계산을 순전파(forward propagation)라 부른다.
왜 층을 여러개 쌓나요?
이론적으로는 2층 신경망으로도 임의의 연속함수를 근사할 수 있다. >> universal approximation theorem 라 부른다.
실제로 학습을 돌릴 때는 2층 신경망으로는 힘들다.
층이 깊을수록 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 빨리 줄어들어 좀 더 효율적으로 학습이 가능하다. 층이 얇으면 필요한 뉴런의 숫자가 기하급수적으로 늘어나서 넓은(wide) 신경망이 되어야 한다.
층이 깊다고해서 최적화가 쉽다고 할 순 없다. 즉 층이 깊을수록 학습하기 어려워 질 수 있다.
결론 : 딥러닝에서 층을 깊게 쌓는 이유는 적은 파라미터를 가지고도 복잡한 패턴을 표현할 수 있기 때문이다.

역전파 알고리즘 : 딥러닝 학습원리
딥러닝은 역전파(backpropagation) 알고리즘을 이용하여 각 층에 사용된 패러미터 \(\{W^{(ℓ)} , b^{(ℓ)}\}^L_{ℓ=1}\)를 학습한다. 빨간색 화살표가 각 층에서 계산된 그레디언트들을 밑에 있는 층으로 전달하는 흐름.
역전파 알고리즘은 먼저 위층 그레디언트를 계산한 뒤 점점 아래층으로 가면서 그레디언트 벡터를 계산하면서 업데이트 하는 방식이다.

즉, 각 층 패러미터의 그레디언트 벡터는 윗층부터 역순으로 계산하게 된다.
이때 합성함수의 미분법인 연쇄법칙을 통해 그레디언트 벡터를 전달한다.

역전파 알고리즘은 합성함수 미분법인 연쇄법칙(chain-rule) 기반 자동미분 (auto-differentiation)을 사용한다.
주의점은 각 노드의 텐서 값을 컴퓨터가 기억해야 미분 계산이 가능하다.
그래서 역전파 알고리즘은 순전파 알고리즘보다 메모리를 많이 사용하게 된다.

예제: 2층 신경망
w1 행렬에 대해 경사하강법을 쓰고싶다! 그래서 미분값을 순차적으로 곱해주는 형태인 역전파 알고리즘이 동작한다.



'AI' 카테고리의 다른 글
| 딥러닝 기초 다지기 (2) (0) | 2022.12.25 |
|---|---|
| 딥러닝 기초 다지기 (1) (0) | 2022.12.25 |
| 인공지능(AI) 기초 다지기 (7) (0) | 2022.12.19 |
| 인공지능(AI) 기초 다지기 (6) (0) | 2022.12.19 |
| 인공지능(AI) 기초 다지기 (5) (0) | 2022.12.18 |



