
코딩하는 해맑은 거북이
딥러닝 기초 다지기 (1) 본문
본 게시물의 내용은 '딥러닝 기초 다지기(부스트코스)' 강의를 듣고 작성하였다.
해당 글은 1. 딥러닝 기초 3가지 파트를 다룬다.
1. 딥러닝 기본 용어 설명
2. Historical Review
3. 뉴럴 네트워크 - MLP
1. 딥러닝 기본 용어 설명
- 인공지능 : 사람의 지능을 모방하는 것.
- 머신러닝 : 무언가를 학습하고자 할 때 데이터를 이용하여 모델을 만드는 것.
- 딥러닝 : 사용하는 모델이 뉴럴 네트워크 구조로 학습하는 것.

- 딥러닝 분야의 중요한 요소 4가지
The data that the model can learn from
The model how to transform the data
The loss function that quantifies the badness of the model
The algorithm to adjust the parameters to minimize the loss
1) Data
풀고자 하는 문제에 의존한다.
- Classification : 이미지를 분류하는 것.
- Semantic Segmentation : 이미지 별 각 픽셀별로 분류하는 것.
- Detection : 이미지 안에 물체에 대해 Bounding-box를 찾는 것.
- Pose Estimation : 이미지에 있는 사람에 2, 3차원 skelecton 정보를 알아내는 것.
- Visual QnA : 이미지와 질문이 있을 때, 질문에 대한 답을 구하는 것.

2) Model
이미지, 문장, 단어가 주어질 때, 이러한 단어를 우리가 직접적으로 알고 싶어하는 Class Label 등으로 바꿔주는 것.
같은 데이터가 주어졌다하더라도 모델의 성질에 따라 결과가 좋을 수도 나쁠 수도 있다.
ex) AlexNet, GoogLeNet, ResNet, DenseNet, LSTM, Deep AutoEncoders, GAN
3) Loss
모델과 데이터가 정해져 있을 때, 모델을 어떻게 학습할 지를 정해주는 것.
Loss function은 이루고자 하는 것에 근사치에 불과하다.
왜냐하면 일반적으로 loss function값이 줄어든다고 해서 원하는 값을 항상 이룬다는 보장이 없기 때문이다.

4) optimization Algorithm
데이터, 모델, loss function이 주어져 있을 때, network를 어떻게 줄일지에 대한 것.
뉴럴네트워크의 파라미터를 loss function에 대해서 1차 미분을 한 정보를 활용하는 것 → SGD
이것을 변형한 Mementum, NAG, Adagrad, Adadelta, Rmsprop 등이 있음
regularizer, regularization : 학습이 오히려 잘 안되게 해주는 효과가 있는 방법을 추가
ex) Dropout, Early Stopping, k-fold validation, Weight decay, Batch normalization, MixUp, Ensemble, Bayesian Optimization
2. Historical Review
- 2012 - AlexNet
ILSVRC 대회에 1등을 한 컨볼루션 신경망(CNN) 구조
224x224 이미지가 들어왔을 때, 이를 분류하는 것.

- 2013 - DQN
영국 스타트업이었던 딥마인드(현재의 구글 딥마인드, 알파고)에서 개발한 알고리즘
강화학습 가능한 심층 신경망을 이용하여 게임 플레이, 오늘날의 딥마인드를 있게한 논문.

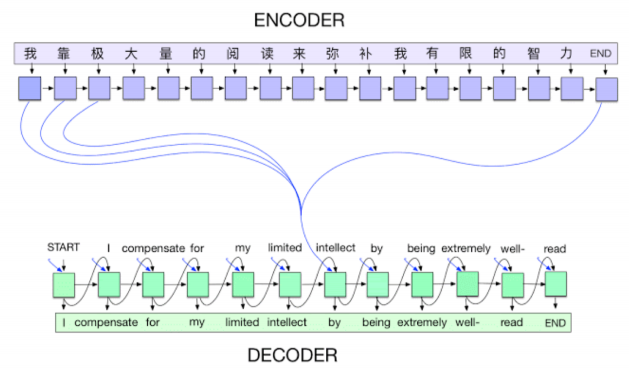
- 2014 - Encoder / Decoder
NMT(Neural Machine Translation) 문제를 풀기 위한 것으로 나왔음. 구글 번역 같은 것.
Sequence-to-Sequence (seq2seq) 모델에서 활용됨.
기계어 번역의 트렌드 시작
- 2014 - Adam Optimizer
딥러닝 학습시킬 때 Adam이 웬만하면 결과가 잘나와서 보통 사용한다.
다양한 hyperparameter search 가 이루어짐. 많은 computing resource 요구됨
- 2015 - GAN (Generative Adversarial Network)
이미지나 텍스트를 어떻게 만들어낼지에 대한 것.
Generator(진짜같은 가짜 생성)와 Discriminator(가짜 여부를 구별)를 경쟁적으로 훈련시켜서 현실적인 가짜를 만드는 방법을 훈련시키는 네트워크.

- 2015 - ResNet (Residual Networks)
네트워크를 어느정도 너무 깊게 쌓으면 학습이 잘 안된다는게(test 했을 때 성능이 잘안나옴) 알려져 있었음.
ResNet이 나온 이후, 깊게 쌓으면 학습이 잘 안되는 건 여전하지만 쌓을 수 있는 네트워크 수를 조금 늘려준 논문

- 2017 - Transformer (논문 제목 : Attention is All you need)
디코더에서 출력단어를 예측하는 시점에서 목표단어와 연관이 있는 입력 단어를 좀더 집중(attention)해서 보정하는 기법임. 2020년도에서는 transformer가 웬만한 구조를 다 대체함

- 2018 - BERT (fine-tuned NLP models) = Bidirectional Encoder Representations from Transformers
자연어처리문제는 보통 language model(쉽게말하면 이전 단어 조합으로 다음 단어를 맞추는 것) 을 학습함.
내가 풀고자하는 문제(날씨 예측, 좋은 뉴스만들기)에 딱 맞는 데이터를 대량으로 수집하는 것은 어려워서 큰 말뭉치를 활용해서 목표로 하는 소수의 데이터에 fine-tuning을 하는 것.
- 2019 - Big Language Models (GPT-X)
OpenAI 에서 발표한 논문. fine-tuned NLP model의 끝판왕.
약간의 fine-tuning을 통해 다양한 문장, 프로그램, 표 등 시퀀스 모델을 만들 수 있음.
가장 큰 강점은 굉장히 많은 파라미터로 되어 있는 것. 175억개의 파라미터
- 2020 - Self-Supervised Learning
분류문제에서 한정된 학습데이터가 주어졌을 때, 모델, loss function을 바꿔가면서 좋은 성능을 내는 것이 일반적이였다면,
학습데이터 외에 라벨을 모르는 데이터(unsupervised data)를 활용해서 분류문제를 푸는 것.
SimCLR: a simple framework for contrastive learning of visual representations
3. 뉴럴 네트워크 - MLP
“Neural networks are computing systems vaguely inspired by the biological neural networks that constitute animal brains.” (wikipedia)
"Neural networks are function approximators that stack affine transformations followed by nonlinear transformations. "
뉴럴네트워크는 어떤 모델을 내가 정의한 함수로 근사하는 function approximators이다.
affine transformations에다가 비선형 연산이 반복적으로 일어나는 모델.
- Linear Neural Networks
가장 간단한 뉴럴네트워크 모델
1차원인 입력, 출력이 있을 때, 이 두 개를 연결하는 모델을 찾는 것.
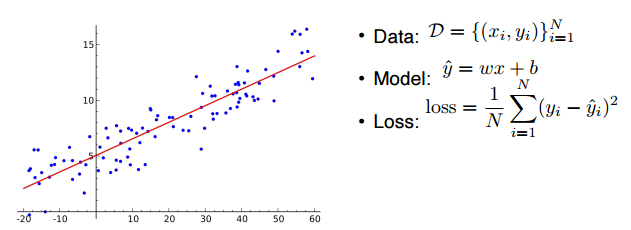
data : 1차원 x, 1차원 y이 n 개 모여 있는 데이터
model : x에서 \(\hat{y}\)으로 가는 w, b를 찾아야 함
loss : 가장 간단한 회귀 문제의 loss function인 MSE 사용. 이루고자 하는 현상이 일어났을 때 값이 줄어든다
* 어떻게 w, b를 찾을까?
backpropagation 방식으로 찾는다.
loss function을 줄이는 것이 목표, 파라미터를 어떻게 바꿨을때 loss function이 줄어들지 - 미분의 기울기값의 역수방향으로 진행. (Gradient Descent)
loss function을 w로 편미분 한 값, b로 편미분 한 값을 구해서, 이 값을 통해 w, b값을 업데이트해서 loss를 줄이는 것.



행렬을 사용해서 m차원을 다룰 수 있음.


* 네트워크를 여러개 쌓으려면?
중간에 Nonlinear transform을 통해 네크워크가 표현할 수 있는 표현력을 극대화하기 위해서는 단순 선형변환보다 activation function을 이용한다. 이런 방식으로 네트워크를 여러개 쌓으면 Multi-Layer Perceptron(MLP)이 된다.



'AI' 카테고리의 다른 글
| 딥러닝 기초 다지기 (3) (0) | 2022.12.25 |
|---|---|
| 딥러닝 기초 다지기 (2) (0) | 2022.12.25 |
| 인공지능(AI) 기초 다지기 (8) (0) | 2022.12.23 |
| 인공지능(AI) 기초 다지기 (7) (0) | 2022.12.19 |
| 인공지능(AI) 기초 다지기 (6) (0) | 2022.12.19 |



