
코딩하는 해맑은 거북이
[머신러닝] Feature 본문
해당 글은 아래의 5가지를 다룬다.
1. Feature
2. Feature Vector
3. Feature Space
4. Feature Extraction
5. Traditional ML vs Current DL
Check.
Q. feature vector란 무엇일까요?
특징(feature) 이란, 샘플(데이터)을 잘 설명하는 측정가능한 속성이다. 특징을 통해 특정 샘플을 수치화하여 나타낼 수 있다.
특징벡터(feature vector) 란 피쳐(feature)들의 집합이다. 굳이 벡터로 표시하는 이유는 수학적으로 다루기 편하기 때문이다.
데이터별로 어떤 특징을 가지고 있는지 찾아내고, 그것을 토대로 데이터를 벡터로 변환하는 작업을 특징추출(feature extraction) 이라고 한다.
특징 공간(feature space) 이란 관측값들이 있는 공간을 의미한다. 이 특징 공간은 여러 차원으로 구성될 수 있다. 어떤 데이터를 특징공간의 하나의 벡터로 표현하는 경우, 여러 특징 변수가 특징벡터에 영향을 줄 수 있다. 예를들어, 특징 변수가 하나인 데이터는 1차원 특징 공간에 나타나고, 특징 변수가 N개라면 N차원의 특징 공간에 나타낼 수 있다.
d-차원 데이터의 특징 벡터는 다음과 같이 표시된다.
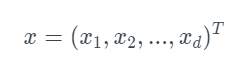
💡 분야에 따른 피처벡터의 의미
컴퓨터비전(이미지)에서의 특징은 edge, corner 등을 의미한다. 픽셀 값이 급격히 변화하는 곳, 밝기의 변화, 색상의 변화, 그래디언트의 방향 등의 매칭 정보등을 특징으로 삼는다. SIFT, SURF 등의 방법이 존재한다.
자연어처리(텍스트) 에서의 특징은 단어, 형태소, 서브워드, 토큰 등으로 표현될 수 있으며, BOW(Bag-of-Words)는 문서에서 단어의 발생을 설명하는 텍스트의 벡터 표현이다. 만약 8개의 단어로 이루어진 문장을 BoW로 만들면, 8차원(dimension)의 vector로서 하나의 단어를 표현할 수 있다.
정형데이터에서의 특징은 각 attribute(열)를 의미한다. 키, 나이, 국적 등이 특징으로 사용될 수 있다.
- Feature 란
머신러닝에서 데이터의 특징을 나타내는 변수이다. 즉, 샘플을 잘 설명하는 특징으로, 자료의 형태는 Categorical (범주형) 2가지, Continous (연속형) 2가지 총 4가지 타입이 존재한다.
- Categorical (범주형)
1) Nominal Variable (명목 변수)
변수의 값이 측정 대상을 특정한 범주(category) 안에 들어가게 하지만 해당 범주간에는 순위는 존재하지 않는 것이다. 예를 들면 사람의 혈액형과 같이 변수의 값(A, B, O or AB)이 대상을 특정 범주에 들어가게는 하지만, 각각의 혈액형은 순위를 매길 수 없는 경우이다
2) Ordinal Variable (순위 변수)
변수의 값이 측정 대상을 특정 범주에 들어 가도록 하면서, 변수의 값이 순위를 가지는 경우를 말한다. 예를 들자면 대학교 수업 성적(A > B > C > D > F) 와 같은 것들이 있다.
- Continous (연속형)
1) Ratio Variable (비율 변수)
등간변수가 가지고 있는 0의 값이 절대적인 0의 값을 가지고 있는 변수이다. 예를 들어, 무게가 0일 때는 정말 무게가 0이라는 것을 알고, 소득이 0이면 정말 소득이 없다는 것을 아는 것처럼, 인위적으로 만들어진 0이 아닌 변수를 비율변수라 할 수 있다. 이러한 비율변수의 예로는, 연령 / 무게 / 시간 / 거리 / 소득 / 교역량 등이 있다.
2) Interval Variable (간격 변수)
측정 대상의 순서와 측정 대상 간의 간격을 알 수 있는 변수로, 그 사이의 간격이 같은 변수를 말한다. 등간변수가 갖는 0의 값은 사람이 만든 인위적인 0이다. (0의 값이 절대적인 0이 아닌 사람이 만든 0이라 실질적으로 0이 아닐 수 있다)
* Feature의 개수
Feature 변수가 n개이면 n차원의 특징 공간을 가진다.
(데이터의 차원이 증가할수록(Feature가 증가할수록) 데이터를 표현하는 공간이 증가한다. 이를 차원의 저주라고 한다.)
- Feature Vector
Feature들의 집합을 의미한다. Raw Data(원시 데이터)로 부터 머신러닝에 적합한 데이터로 정제하는 것을 특징 추출(Feature extraction)이라 한다.
- Feature Space
관측값들이 있는 공간을 뜻한다. 이 특징공간은 여러 차원으로 구성될 수 있다.
- 특징추출(feature extraction)
머신러닝에서 컴퓨터가 스스로 학습하려면, 즉 컴퓨터가 입력받은 데이터를 분석하여 일정한 패턴이나 규칙을 찾아내려면 사람이 인지하는 데이터를 컴퓨터가 인지할 수 있는 데이터로 변환해 주어야 한다. 이때 데이터별로 어떤 특징을 가지고 있는지를 찾아내고, 그것을 토대로 데이터를 벡터로 변환하는 작업을 특징추출(feature extraction)이라고 한다.
즉, 기존 Feature들의 조합으로 유용한 Feature들을 새롭게 생성하는 과정이다. 고차원의 원본 Feature 공간을 저차원의 새로운 Feature 공간으로 투영한다.

* Feature Selection vs Feature Extraction
- Feature Selection : 기존 Feature들의 부분 집합(하위 집단)을 유지
- Feature Extraction : 기존 Feature에 기반하여 새로운 Feature들을 생성

- Traditional ML vs Current DL
Tradional Machine Learning
Domain 지식을 활용하여, 가설을 세워서 전처리를 수행한후 Feature들을 추출한다. 이렇게 추출된 Feature들을 통해 Model을 만들기 떄문에 사람이 해석하기 용이한 모델이 만들어진다. 하지만, 사람이 고려하지 못한 Feature들이 존재 할 수 있다.
Current Deep Learning
최소한의 Raw Data(원시 데이터)에 대한 전처리를 수행하여, 모델을 학습한다. 스스로 학습하고 결과를 보여주기 때문에 구현하기에 용이하다. 그리고 미처 발견하지 못한 특징도 활용할 수 있다. 그렇기 때문에 사람이 해석하기에 적합하지 않다.
[참고자료]
https://velog.io/@chemestry100/Feature-%ED%8A%B9%EC%A7%95%EC%9D%B4%EB%9E%80
Feature (특징)이란
샘플을 잘 설명하는 특징.데이터 타입엔 4가지의 특징이 존재함: \- Categorical (범주형) Nominal Variable Ordinal VariableContinous (연속형)Ratio VariableInterval Variable머신러닝, 인공지능
velog.io
[통계학] 자료로서의 변수 구분 및 개념 정리 – 모두의매뉴얼
통계학에서 변수(variable)란 각 측정 단위에 대해서 측정 하려고 하는 특성을 이야기 합니다. 아래는 여러 종류의 변수에 대한 개념을 정리한 것입니다. 질적변수 vs 양적변수 질적변수(Qualitative va
triki.net
https://likesocialwelfare.tistory.com/9
01. 변수에 대해서(명목변수, 서열변수, 등간변수, 비율변수)
prologue(프롤로그) 갑자기 변수에 대해서 이야기하는 것이 조금은 당황스러울 수도 있다. 조사론에 대한 끄적거림에 갑자기 왠 변수들 이야기인지.. 하지만, 설문지를 만들고 분석을 하는 데 있어
likesocialwelfare.tistory.com
https://bioinformaticsandme.tistory.com/188
Feature selection vs Feature extraction
Feature selection vs Feature extraction Start BioinformaticsAndMe 1. Feature selection (특징 선택) : Feature selection(=Variable selection)은 관련없거나 중복되는 Feature들을 필터링하고 간결한 subs..
bioinformaticsandme.tistory.com
'AI' 카테고리의 다른 글
| [머신러닝] 엔트로피(Entropy)와 크로스 엔트로피(Cross-Entropy) (0) | 2022.07.22 |
|---|---|
| [머신러닝] Frequentist(빈도주의) vs Bayesian(베이지안) (0) | 2022.07.21 |
| [머신러닝] PCA, SVD, LDA, LSA (0) | 2022.07.18 |
| [머신러닝] Cross Validation (CV, 교차검증) (0) | 2022.07.17 |
| [머신러닝] Bias-Variance tradeoff, Regularization (0) | 2022.07.16 |



