
코딩하는 해맑은 거북이
[머신러닝] Cross Validation (CV, 교차검증) 본문
해당 글은 아래의 3가지를 다룬다.
1. Cross Validation
2. Cross Validation의 장단점
3. Cross Validation의 종류
Check.
Q. Cross Validation은 무엇이고 어떻게 해야하나요?
cross validation(교차검증)이란 train(학습) 데이터로 학습한 모델이, 학습에 사용되지 않은 validation(검증) 데이터를 기준으로 얼마나 잘 동작하는지 확인하는 것이다. 여기서 주의할 점은 train 데이터셋과 validation 데이터셋에는 test 데이터셋이 포함되면 안된다는 것이다.
교차검증을 통해 얻을 수 있는 장단점은 아래와 같다.
- 적은 데이터에 대한 validation 신뢰성을 높일 수 있다.
- 모든 데이터셋을 훈련에 활용할 수 있으므로 데이터 편중을 막을 수 있다. (k-fold 경우)
- 검증 결과에 따라 더 일반화된 모델을 만들 수 있다.
- 모델 학습에 오랜 시간이 소요된다.
교차검증 기법의 종류는 아래와 같다. (validation 데이터셋을 어떻게 지정하느냐에 따라 달라진다.)
- 홀드 아웃 교차검증(Holdout Cross Validation)
- K-겹 교차검증(K-fold Cross Validation)
- 계층별 k-겹 교차검증(Stratified K-Fold Cross Validation)
홀드 아웃 교차검증
홀드아웃 교차검증방법은 일정한 비율의 validation 데이터셋 하나를 지정하여 검증 데이터셋으로 사용하는 것이다. 홀드아웃 교차검증을 사용하는 경우, 두가지 문제점이 존재한다.
1. validation 데이터셋으로 지정된 부분의 데이터가 학습셋으로 사용되지 않는다는 문제
2. validation 데이터셋에 편향되도록 모델을 조정하게 된다는 문제
이를 해결하기 위해 k-겹 교차검증이 등장했다.
k-겹 교차검증
k-겹 교차검증 방법은 train 데이터를 k개의 fold로 나누어, 그 중 하나의 fold를 validation 데이터셋으로 삼아 검증하는 방법을 k번 반복하여, 그 평균을 결과로서 사용하는 방법이다. 세부적인 동작방법은 다음과 같다.
1. train 데이터셋을 k개의 fold로 나누고, 그 중 하나를 validation 데이터셋으로 지정한다.
2. validation 데이터셋을 제외한 나머지 폴드들을 train 데이터셋으로 사용하여 모델을 학습한다.
3. 학습한 모델을 1번에서 지정해둔 validation 데이터셋으로 검증하고, 그 검증 결과를 저장해둔다.
4. 모델을 초기화한 후, 기존 validation 데이터셋이 아닌 다른 fold를 validation 데이터셋으로 지정하고, 2번 과정부터 다시 수행한다.
5. 모든 fold들이 한번씩 validation 데이터셋으로 사용된 후에는, 저장해둔 검증결과의 평균을 내어, 그것을 최종 validation 결과로 사용한다.
그러나 k-겹 교차검증 방법은 랜덤하게 validation 데이터셋을 지정하게 되므로, 편향된 데이터로 이뤄진 폴드가 생성될 수 있다는 단점이 있다. 이를 해결하기 위해서 계층별 k-겹 교차검증 방법이 등장했다.
계층별 k-겹 교차검증
계층별 k-겹 교차검증 방법은 k-겹 교차검증 방법에서 fold를 나눌때, 랜덤하게 fold를 지정하는 것이 아닌, 각 클래스별 비율을 고려하여 fold를 구성하는 방법이다.
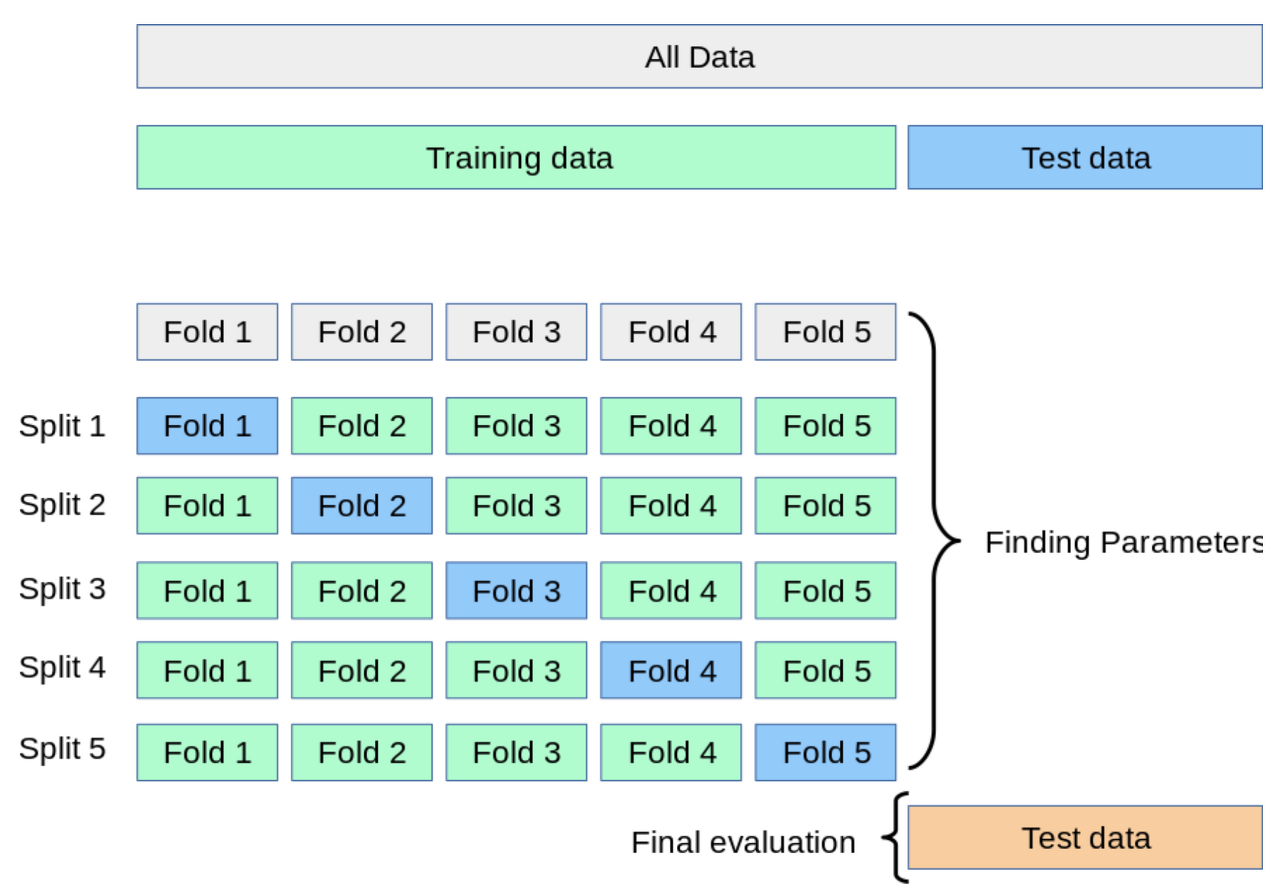
💡 왜 test 데이터셋 만으로 검증하면 안될까?
모든 train 데이터셋을 학습하고, test 데이터셋으로 검증한 결과를 확인한다고 하자. 개발자는 test 데이터셋 점수를 높이기 위해, test 데이터셋에 편향되도록 모델을 튜닝하게 될 것이다. 그러나 중요한 것은 test 데이터셋에 대한 정확도를 높이는 것 뿐만아니라, 모델의 일반적인 정확도를 높이는 것이다. 어떤 데이터가 들어와도 일정하게 높은 정확도를 보여주는 모델이 좋은 모델이라 할 수 있으므로, validation 데이터셋과 test 데이터셋을 분리하여 검증하는 과정을 통해, 모델을 일반화시켜야 한다.
- Cross Validation (CV, 교차검증)
: 데이터는 label이 있는 Train, Test Set으로 구성되어 있다. 이를 고정된 Train set과 Test set으로 학습과 평가를 하고, 반복적으로 모델을 튜닝하다보면 Test set에만 과적합되어버리는 결과가 생겨버린다. 이를 해결하고자 하는 것이 Cross Validation 이다.
* 데이터셋을 train/validation/test 로 나누는 방법과 train/test 방법이 따로 존재하는 것 같다.
- Cross Validation 의 장단점
장점
1) 모든 데이터셋을 평가에 활용할 수 있다.
- 평가에 사용되는 데이터 편중을 막을 수 있다. (특정 평가 데이터셋에 overfitting되는 것을 방지할 수 있다.)
- 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다.
2) 모든 데이터셋을 훈련에 활용할 수 있다.
- 정확도를 향상시킬 수 있다.
- 데이터 부족으로 인한 underfitting을 방지할 수 있다.
단점
Iteration 횟수가 많기 때문에 모델 훈련/평가 시간이 오래 걸린다.
- Cross Validation 의 종류
1) Holdout method (홀드아웃 방법)

이 방법은 데이터셋을 Train set과 Test set 두 세트로 나누는 과정을 의미한다. 보통 train : test = 9 : 1 또는 7 : 3 비율이 가장 자주 쓰인다.
- Iteration을 한번만 하기 때문에 계산 시간에 대한 부담이 적은 것이 장점이다.
- Train set이 작으면 모델 정확도의 분산이 커짐 (underfitting)
- Train set이 커지만 test set으로 부터 측정한 정확도의 신뢰도 하락 (overfitting)
* Random subsampling
이를 해결하기 위해서 일단 더 많은 데이터를 수집하는 것이 낫고, 한정된 데이터에서 최고의 효율을 가지기 위해 나온 것이 Random Subsampling 이다. 한정되어 있는 데이터에서 train set과 test set을 바꿔가면서 Holdout을 반복적으로 실행하는 것을 의미한다.
2) k-fold cross validation (k-겹 교차 검증)

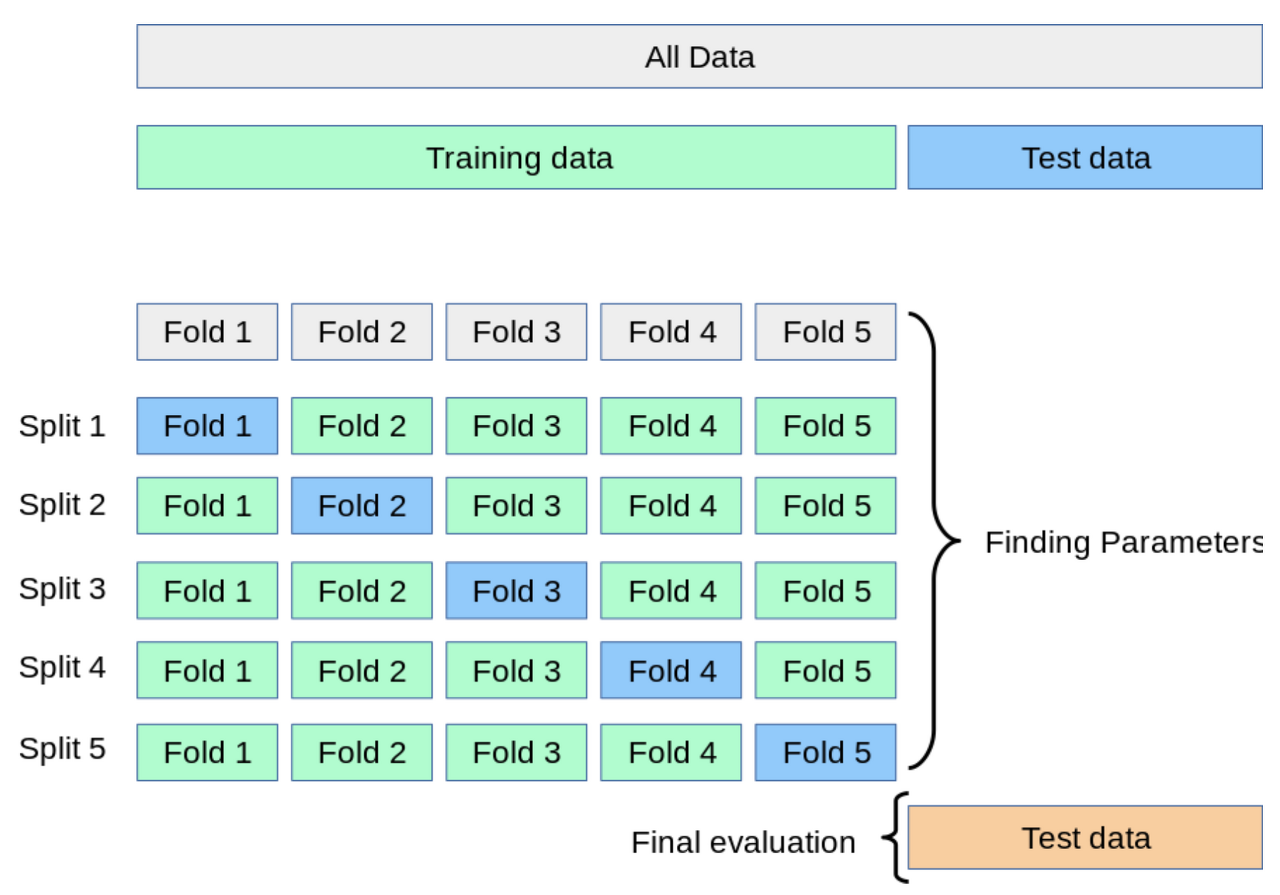
k-fold cross validation은 가장 일반적으로 사용되는 교차 검증 방법이다. 전체 데이터셋을 Train set과 Test set으로 나누고, Train set을 (Train set+Validation set)으로 사용하기 위해 k개의 폴드로 나눈다. 나눠진 폴드 중 첫번째를 Validation set으로 사용하고, 나머지 폴드를 Train set으로 사용한다. 차례대로 다음 폴드를 Validation set으로 사용하여 반복한다. 총 k개의 성능 결과가 나오며, 이 k개의 평균을 해당 학습 모델의 성능이라고 한다.
- 모든 데이터를 train set과 validation set에 쓸 수 있고 overfitting의 염려도 크지 않지만, 시간이 오래 걸린다.
3) Stratified k-fold cross validation (계층별 k-겹 교차검증)

Stratified k-fold cross validation은 주로 Classification 문제에서 사용되며, label의 분포가 각 클래스별로 불균형을 이룰 때 유용하게 사용되며, 랜덤하게 fold를 지정하는 것이 아닌, 각 클래스별 비율을 고려하여 fold를 구성하는 방법이다. label의 분포가 불균형한 상황에서 Sample의 Index순으로 데이터 폴드 세트를 구성하는 것은 데이터를 검증하는데 치명적인 오류를 야기할 수 있으므로, 데이터의 label의 분포까지 고려해주어 각 훈련 또는 검증 폴드의 분포가 전체 데이터셋이 가지고 있는 분포에 근사하게 된다.
4) Leave-p-out cross validation (LpOPO, 리브-p-아웃 교차검증)
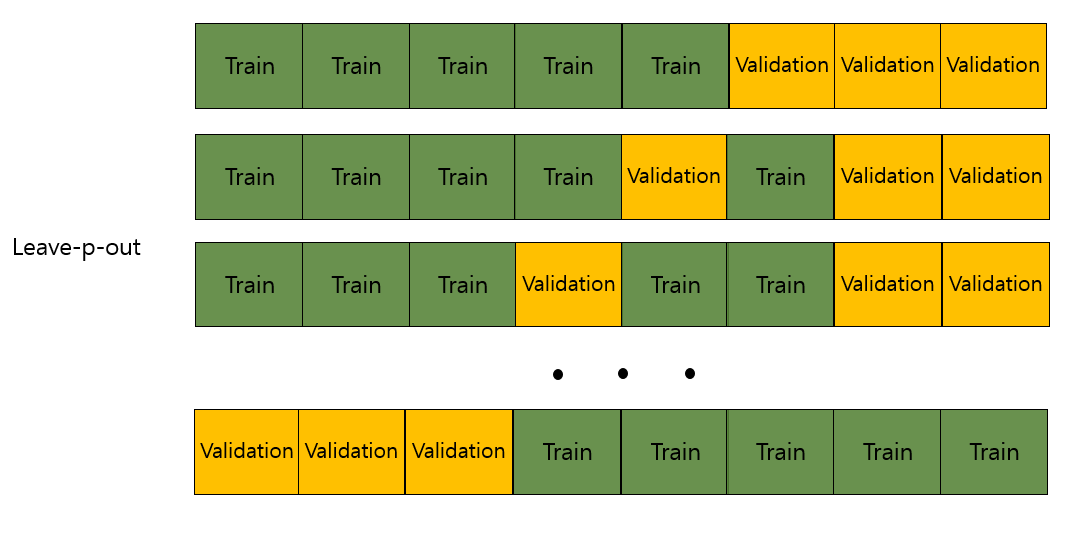
Leave-p-out cross validation은 전체 데이터 중에서 p개의 샘플을 선택하여 validation set으로 사용하고, 나머지 데이터를 train set으로 사용하는 방법이다. 이 방법은 구성할 수 있는 데이터 폴드 세트의 경우의 수가 매우 크기 때문에, 계산 시간에 대한 부담이 매우 큰 방법이다.
- iteration 횟수 : nCp
5) Leave-one-out cross validation (LOOCV)
Leave-p-out cross validation에서 p=1인 경우를 말한다. Leave-p-out cross validation보다 계산 시간에 대한 부담을 줄어들고, 더 좋은 결과를 얻을 수 있기 때문에 선호된다. Validation set에 사용되는 데이터 갯수가 1개 이기 때문에, 나머지 모든 데이터를 train set으로 사용할 수 있다는 것이 장점이다.
[참고자료]
https://m.blog.naver.com/ckdgus1433/221599517834
교차 검증(cross validation)
이번 시간에는 머신러닝에서 평가에 필수적으로 사용되는 교차 검증(cross validation)에 대해서 알아보자....
blog.naver.com
https://wooono.tistory.com/105
[ML] 교차검증 (CV, Cross Validation) 이란?
교차 검증이란? 보통은 train set 으로 모델을 훈련, test set으로 모델을 검증한다. 여기에는 한 가지 약점이 존재한다. 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, 결
wooono.tistory.com
'AI' 카테고리의 다른 글
| [머신러닝] Feature (0) | 2022.07.20 |
|---|---|
| [머신러닝] PCA, SVD, LDA, LSA (0) | 2022.07.18 |
| [머신러닝] Bias-Variance tradeoff, Regularization (0) | 2022.07.16 |
| [인공지능기초] Tree Search(Informed Search) (0) | 2022.07.15 |
| [컴퓨터비전] Object Detection, BBOX, Matrix (0) | 2022.07.15 |



