
코딩하는 해맑은 거북이
[딥러닝] Normalization, Standardization 본문
해당 글은 아래의 3가지를 다룬다.
1. Normalization
2. Normalization을 왜 할까?
3. Normalization의 종류
Normalization
: 데이터의 범위를 사용자가 원하는 범위로 제한하는 것.
예를 들어, 이미지의 데이터의 경우 픽셀 정보를 0~255 사이의 값으로 가지는데, 이를 255로 나누어주면 0.0~1.0 사이의 값을 가지게 된 다. 이러한 행위를 Feature들의 Scale을 정규화(Normalization) 한다고 한다. 이를 Min-Max Normalization 이라고 부르기도 한다.

다른 경우는 Scaling을 넘어서 표준정규분포를 갖게 하고 싶으면 데이터의 평균과 표준편차를 사용하면 된다. 이 경우는 표준화(Standardization) 라고 하며, 정규화 방법 중 하나라고 볼 수 있다. 이는 Z-Score를 구하는 방법을 의미한다. 그래서 Z-Score Normalization 이라고 불리기도 한다.

Normalization을 왜 할까?
학습을 더 빨리하고, Local Optimum에 빠지는 가능성을 줄이는 장점이 있다. 즉, Optimal Solution으로의 수렴 속도가 빨라진다는 것이다.
직관적인 이해를 위해 아래의 그림을 보자.
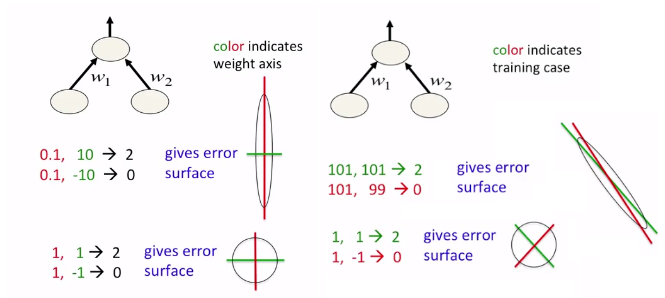
loss를 w1, w2를 축으로 하는 parameter space에서 표현하고, optimal이 원점에 있다고 하자. 확실히 정규화 전에는 loss function의 형태가 Elogated(가늘고 길죽한) 되어 있지만, 정규화 후에는 Spherical(구 모양)해 진 것을 볼 수 있다.

그리고 위 그림처럼 Spherical 할 때, 즉 정규화를 했을 때 optimal solution을 더 빠르게 찾아간다는 것이다.
* Normalization의 장점
1) 학습의 안정화: Gradient vanising/exploding 문제를 해결할 수 있음
2) 학습시간의 단축: learning rate를 크게 할 수 있음
3) 성능 개선: local optimum에서 빨리 빠져나올 수 있음
- 큰 값을 갖는 변수에 편향되지 않을 수 있다.
- 내부 공변량 변화(Internal Covariate Shift)를 줄일 수 있다.
cf) 내부 공변량 변화(Internal Covariate Shift) : 딥러닝 모델 내부에 하나의 은닉층에 서로 다른 범위의 입력이 들어오는 것.
- 정규화를 통해 기울기의 크기를 제한함으로써, 손실함수의 표면을 매끄럽게 한다.
- 정규화를 통해 Gradient의 미분값이 0이 되지 않도록 특정 범위로 제한하기 때문에 최적화를 더 빠르게 만든다.
Normalization의 종류
1. Data Normalization
데이터의 Feature들의 분포(Scale)를 조절하여 균일하게 만드는 방법이다.
필요한 이유는 데이터 Featrue 간 Scale 차이가 심하게 날 때, 큰 범위를 가지는 Feature(ex. 가걱)가 작은 범위를 가지는 Feature(ex. 나이)보다 더 강하게 모델에 반영될 수 있기 때문이다. 그러므로 정규화를 통해 큰 값을 갖는 변수에 편향되지 않을 수 있다.
2. Batch Normalization
내부 공변량 변화(Internal Covariate Shift)를 막기 위한 가장 간단한 방법으로,
매 순간의 input을 평균 0, 표준편차 1인 분포로 정규화 시켜주는 것이며, 이 행위를 whitening이라고도 한다.
( → 표준정규분포를 만들어 주는 것 : Standardization)
'매 순간'의 의미는 weight가 training 되는 순간. 즉, 매 mini-batch 마다 whitening 하는 기법이다.
또한, 이 정규화 방법은 Gradient Vanishing / Gradient Exploding이 일어나지 않도록 하는 아이디어 중의 하나입니다.
- Gradient Vanishing : 신경망에서 손실 함수의 gradient 값이 0에 근접하며, 훈련을 하기 힘들어지는 문제
- Gradient Exploding : 심층 신경망 또는 RNN에서 error gradient가 축적되어, 가중치 업데이트시 overflow되거나 NaN값이 되는 현상
한 Feature dimension(= Channel)대해 모든 batch를 정규화한다 (= batch 차원의 정규화)

* 2단계 과정

1) Normalize pre-activation function : pre-activate된 샘플을 standard normalize 한다.

2) Scale and Shift : standard normalize된 샘플의 variance와 bias를 조절할 수 있는 γ, β를 부과해서 parameterize 한다.
→ variance와 bias를 다시 조절하는 이유는 sigmoid의 경우는 중심에 분포가 몰려있는 것이 효과적이지만, 다른 activation은 그렇지 않기 때문이다. 즉, 학습을 통해 γ, β를 학습해 적절한 분포를 가지게 하기 위함이다.

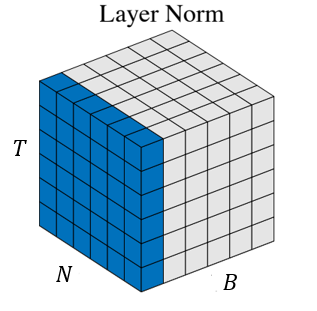
3. Layer Normalization
위에서 Batch Normalization에서 mini-batch 샘플의 feature별 평균과 분산을 구해서 표준정규분포로 전환했다. 그런데 batch size가 1이라면 불가능 하다는 문제점이 있다. 이러한 문제점을 해결하기 위해 batch에 있는 모든 feature의 평균과 분산을 구하는 방법으로 Layer Normalization이 있다. 즉, 각 hidden node의 feature별 평균과 분산이 아닌 hidden layer 전체의 평균과 분산으로 정규화한다. 그 이후 과정은 Batch Normalization과 완벽히 동일하다.
모든 Feature dimension(= Channel)에 대해 하나의 layer만 평균과 분산을 정규화한다. (= Feature 차원의 정규화)
4. Instance Normalization
1개의 batch 내의 각 Feature dimension(= Channel)별로 평균과 분산을 정규화한다.
주로 style transfer에 쓰이는 방법이다. Instance Normalization을 통해 Contents 요소만 살리고 화풍을 지울 수 있다고 한다.

5. Group Normalization
Batch Normlization을 하고 싶지만 Segmentation, video와 같이 메모리 소비 때문에 어쩔 수 없이 batch size가 제약될 때 대체하기 위한 방법으로, Feature dimension(= Channel) 방향으로 Group을 지어서 정규화를 진행하고, 아래의 예시처럼 2로 설정하면 2개의 group으로 나누어 정규화를 진행한다. 만약 Group이 채널 전체면 Layer Normalization, 1개면 Instance Normalization 이 된다.

6. Weight Normalization
mini-batch를 정규화하는 것이 아니라 layer의 가중치를 정규화한다. Weight Normalization은 레이어의 가중치 w를 아래와 같이 re-parameterize(재매개변수) 시킨다. Weight Normalization은 경우에 따라 Batch Normalization보다 빠르다. 예를 들어, CNN의 경우 가중치의 수는 입력의 수보다 훨씬 작다. 즉, Batch Normalization보다 Weight Normalization이 연산량이 훨씬 적다는 의미이다. Batch Normalization의 경우에는 입력값의 모든 원소를 연산해야하고, 이미지 등의 고차원 데이터에서 연산량이 매우 많아집니다. 그렇기에 Weight Normalization이 더 빠른 경우가 생기게 된다.
다만 이 방법은 평균을 0으로 보장해주지 못하기 때문에 mean-only batch normalization과 함께 사용하기를 제안한다. 이 방법은 Weight Normalization보다 속도가 낮지만, 표준편차를 계산하지 않으므로 Batch Normalization보다는 연산량이 적다.

[참고자료]
https://sonsnotation.blogspot.com/2020/11/8-normalization.html
[머신러닝/딥러닝] 8. Normalization
sonsnotation.blogspot.com
https://light-tree.tistory.com/132
딥러닝 용어 정리, Normalization(정규화) 설명
제가 공부한 내용을 정리한 글입니다. 제가 나중에 다시 볼려고 작성한 글이다보니 편의상 반말로 작성했습니다. 잘못된 내용이 있다면 지적 부탁드립니다. 감사합니다. Normalization Data Normalizatio
light-tree.tistory.com
https://sanghyu.tistory.com/32?category=1120072
[PyTorch] 시계열 데이터를 위한 다양한 Normalization기법 (BatchNorm1d, GroupNorm 사용법)
Normalization Neural network의 깊이가 점점 깊어질수록 학습이 안정적으로 되지 않는 문제가 발생한다. 이런 학습의 불안정화의 원인으로 'internal covariance shift'가 언급되었다. 이는 딥러닝에서 각 layer.
sanghyu.tistory.com
https://subinium.github.io/introduction-to-normalization/
Introduction to Deep Learning Normalization
수 많은 정규화들을 한번 가볍게 읽어봅시다.
subinium.github.io
Batch Normalization에 대해서 알아보자
BN의 전체적인 역사와 개념들을 알아보는 시간을 가져볼까요?
velog.io
'AI' 카테고리의 다른 글
| 인공지능(AI) 기초 다지기 (2) (0) | 2022.12.12 |
|---|---|
| 인공지능(AI) 기초 다지기 (1) (0) | 2022.12.12 |
| [머신러닝] 선형회귀(Linear Regression), 로지스틱 회귀(Logistic Regression), 소프트맥스 회귀(Softmax Regression) (0) | 2022.07.27 |
| [머신러닝] 엔트로피(Entropy)와 크로스 엔트로피(Cross-Entropy) (0) | 2022.07.22 |
| [머신러닝] Frequentist(빈도주의) vs Bayesian(베이지안) (0) | 2022.07.21 |


