
코딩하는 해맑은 거북이
[컴퓨터비전] Conditional Generative Model 본문
본 게시물의 내용은 '부스트캠프 AI Tech - CV (오태현)' 강의를 듣고 작성하였다.
해당 글은 아래의 3가지를 다룬다.
📌Conditional generative model
📌 Image translation GANs
📌 GAN 응용
📌Conditional generative model
왼쪽 그림과 같이 가방의 스케치가 주어졌을 때, 실제 가방 같은 이미지로 변환하는 task를 수행한다고 하자.
입력과 출력 이미지의 도메인이 다른 이러한 종류의 task는 Image Translation이라 한다.
마치 언어를 번역하는 것과 같은 유사한 기능을 하기 때문이다.
sketch of a bag 이라는 condition(조건)이 주어지고, 해당 condition에 따라 이미지 X를 생성하는 형태의 task를 수행하는 모델을 Conditional generative model이라 한다.
해당 Generative model은 일반적으로 확률 분포를 모델링하는 기법이기 때문에, 모델링된 확률 분포에서 condition에 따라 sampling을 수행하는 개념이라고 볼 수 있다. → P(X|sketch of a bag)

- Generative model vs. Conditional generative model
Generative model은 P(X)로 영상이나 샘플은 생성할 수 있지만 조작은 할 수 없었다. 즉, 랜덤하게 샘플링만 가능하다.
그래서 사용자의 의도가 반영된 생성이 유용하게 활용될 수 있기 때문에 condition이 주어진 이러한 모델을 Conditional generative model 이라 한다.

- Conditional generative model 응용 사례
audio super resolution : 저음질의 오디오를 고음질로 변환
machine translation : 중국어를 영어로 번역
article generation : 제목이 주어졌을 때 글 작성
- Generative Adversarial Network
위조지폐범(Generator)이 위조지폐(가짜 이미지)를 만들면,
경찰(Discriminator)이 지폐를 보고 진짜인지 위조인지 판별하는 역할을 하게 된다.
위조지폐범(Generator)은 경찰이 위조지폐를 판별하지 못하도록 적대적으로 학습하고,
경찰(Discriminator)은 위조지폐를 더 잘 구별할 수 있도록 학습하면서
Discriminator의 성능이 높아지면, Generator의 성능도 같이 높아지게되는 상호작용을 기반으로 더 뛰어난 생성모델과 판별모델이 탄생되는게 GAN 이다.

- GAN vs. Conditional GAN
Conditional GAN의 구조는 GAN의 구조와 유사하나, 입력에서 latent vector Z 뿐만 아니라 conditional 정보를 제공하기 위해 C를 입력으로 추가해준다.

- Conditional GAN 응용
image-to-image translation :
- Style transfer : 입력 이미지의 스타일을 변경
- Super resolution : 저해상도의 이미지를 고해상도로 변환
- Colorization : 흑백사진을 컬러사진으로 바꿔주는 방법
ex) Super resolution
Super resolution은 저해상도의 이미지를 고해상도의 이미지로 변환해주는 Conditional GAN의 대표적인 예시이다.
구조로는 저해상도 이미지를 generator의 입력으로 주고, discriminator의 입력으로 real data인 고해상도 이미지(Real HR Image)와 generator가 생성한 고해상도 이미지(Fake HR Image)를 줘서 두 개의 입력이 비슷한 통계적 특성을 갖는지 판별하는 형태로 되어있다.
해당 문제를 Conditional GAN, Conditional generative model로 풀어야 하는 것은 아니다.
이전에는 CNN 구조를 활용해서 MAE(L1) 혹은 MSE(L2) Loss를 사용해서 naive한 regression model을 구현해서 수행할 수 있었다.


하지만, Naive Regression model을 활용하면, 해상도는 높아지지만 여전히 흐릿한 이미지를 얻게 된다.
이유는 픽셀 자체의 intensity 차이인 loss를 이용하기 때문에, generator가 적당한 평균적인 픽셀 값으로 이미지를 생성하도록 학습되기 때문이다.

그런데, GAN은 discriminator가 그러한 트릭을 통해 생성된 이미지를 대부분 가짜로 판별해내기 때문에 이러한 문제를 완화해주었다.

📌 Image translation GANs
앞서 Image Translation은 한 이미지를 다른 이미지 스타일로 변환하는 것을 의미한다.
- Pix2Pix (2017)
Pix2Pix는 Image Translation이라는 task를 CNN 구조로 학습 기반으로 처음 정리한 연구이다.
- Pix2Pix의 Loss function = L1 loss + GAN loss
Loss function은 L1 loss에 GAN loss를 더해서 realistic output을 만들도록 유도해준다.
GAN loss에 의해 학습되어 real data와 비슷한 생성을 만들어내고,
L1 loss는 ground truth y와 비슷한 이미지를 생성할 수 있도록 가이드 역할을 한다.
그리고 Pix2Pix는 pairwise data(입력 x, Ground Truth y)가 필요한 supervised learning 이다.
하지만, 이러한 pairwise data를 얻는 것을 불가능하거나 굉장히 어렵다.


- CycleGAN
Pix2Pix에서 pairwise data가 필요했었는데, 이에 대한 해결책으로 non-pairwise datasets으로 학습가능한 CycleGAN 모델이 등장했다. non-pairwise datasets은 domain간 translation이 직접적인 대응관계가 존재하지 않는 집합들이다.

- CycleGAN의 Loss function = GAN loss (in both direction) + Cycle-consistency loss
GAN loss는 domain 간의 translate하는 방향이 2개 존재하고, domain간 변환 시 real data와 비슷한 생성을 만들어낸다.
Cycle-consistency loss는 원본 이미지(X)를 변환한 이미지(Y)가 다시 변환했을 때, 원본 이미지(X)와 얼마나 유사한지 판별


GAN loss만 사용하면 입력에 상관없이, 하나의 출력만 계속 나오는 문제인 Mode Collapse가 발생한다.
예를 들어 X → Y로 변환된 이미지가 Y의 임의의 실제 데이터와 유사할 수는 있지만, 그것이 X와 유사하지는 않을 수 있기 때문이다. 즉, GAN loss는 real data와의 유사성만을 보기 때문에 변환 전 원본 이미지와 유사해야한다는 것을 학습할 수 없다. 이러한 문제를 해결하기 위해 Cycle-consistency loss가 도입되었다.

Cycle-consistency loss로 style 뿐만 아니라 content도 유지되도록 해야한다는 것을 강조하였다.
Cycle-consistency loss는 원본 이미지(X)를 변환한 이미지(Y)가 다시 변환했을 때, 원본 이미지(X)와 얼마나 유사한지 판별하는 것인데, 즉 원본이미지(X)와 (X → Y → X) 가 서로 유사하도록 학습하게 한다.
그래서 해당 loss를 계산하는 방법은 self-supervision 이다.

- Perceptual loss
GAN은 많은 경우에 high-quality image를 얻기 위해 사용하는데, train하기 어렵다는 단점이 있다.
그럼 high-quality image를 얻기 위한 다른 방법은 없을까에서 나온 것이 Perceptual loss이다.

* GAN loss vs. Perceptual loss
- GAN loss
- 학습과 코드 구현이 상대적으로 어렵다.
- pre-trained network가 필요없다. 그래서 다양한 애플리케이션에 적용가능하다.
- Perceptual loss
- 학습과 코드 구현이 간단하다.
- learned loss를 측정하기 위해 pre-trained network가 필요하다.
Perceptual loss를 통해서 Image Transform Net을 학습하는 방법을 알아보자.
Image Transform Net을 통해 나온 변환된 이미지(transformed image)가 \(hat(y)\)이고
VGG-16 모델로 pre-trained network를 사용하고, 이를 통해 feature를 뽑는다. 사전학습된 모델은 학습 중에는 Fixed-Network이다.

* Feature reconstruction loss
transformed image가 원본 이미지(X)의 content를 그대로 유지하고 있는지 권장해주는 것이 content target 이다.
이는 원본 이미지(X)를 넣어주는 것이 일반적이다. 그리고 content target을 VGG-16 모델을 거쳐 나온 feature를 생성한다.
content target에서 온 feature map와 transformed image에서 온 feature map를 비교해서 L2 loss로 loss를 계산한다.

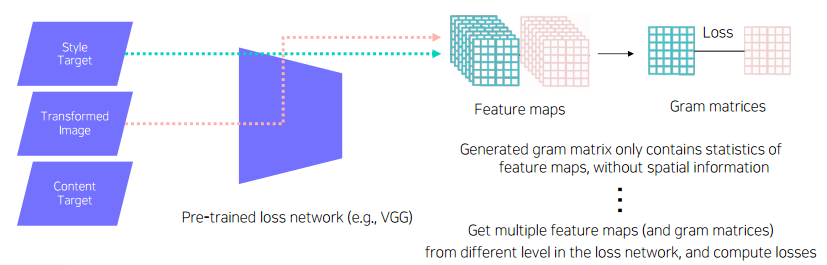
* Style reconstruction loss
style target은 transformed image에도 변환하고자 하는 style이 반영되어 있는지 검사하는 것이고, 변환하고 싶은 style 이미지가 들어간다. content target과 마찬가지로 VGG-16 모델을 거쳐 나온 feature를 생성한다.
그런데 content target과 달리, style target에서 온 feature map와 transformed image에서 온 feature map에서 각각 style을 뽑아내기 위해 한번 더 연산을 수행한다. 그러한 결과가 Gram matrix 이다.
Gram matrix 는 각 이미지의 스타일 정보를 인코딩하고 있는 행렬이다.
style target과 transformed image의 Gram matrix를 모두 구하고 이 둘을 비교해서 L2 loss로 loss를 계산한다.
📌 GAN 응용
- Deepfake
존재하지 않는 사람의 얼굴, 목소리, 페이크연설 등을 만들어낸다.
이는 안좋은 영향이 많아서 윤리적인 부분을 고려해서 Deepfake를 detection을 할 수 있는지 챌린지도 열리고 있다.
- Face de-identification
원본 이미지의 프라이버시를 보호하는 쪽으로 약간의 수정을 통해서
사람은 비슷하게 볼 수 있지만, 컴퓨터는 같은 사람으로 인식하지 못하게 하는 방법
- Face anonymization with passcode
얼굴을 익명화하는데 passcode를 조건으로 conditional GAN을 통해 변형하는 방법
- Video translation
다른 사람의 포즈를 어떤 사람에게 재현하는 Pose tranfer,
semantic segmentation map을 통해 realistic한 영상을 생성해내는 Video-to-video translation,
Video-to-video translation를 응용해서 게임에 적용하는 Video-to-game 이 있다.
'AI' 카테고리의 다른 글
| [컴퓨터비전] 3D Understanding (0) | 2023.04.06 |
|---|---|
| [컴퓨터비전] Multi-modal (0) | 2023.04.05 |
| [컴퓨터비전] Instance/Panoptic Segmentation, Landmark Localization (0) | 2023.04.03 |
| [컴퓨터비전] Visualizing CNN (0) | 2023.04.03 |
| [딥러닝] Feature Map, Activation Map, Score Map (0) | 2023.03.30 |



