
코딩하는 해맑은 거북이
[컴퓨터비전] Object Detection 본문
본 게시물의 내용은 '부스트캠프 AI Tech - CV (오태현)' 강의를 듣고 작성하였다.
해당 글은 아래의 내용을 다룬다.
📌 Object Detection
🔷 Two-stage detector (R-CNN들)
🔷 Single-stage detector
🔷 Two-stage detector vs. Single-stage detector
🔷 Detection with Transformer
📌 Object Detection
Instance segmentation과 Panoptic segmentation은 Semantic segmentation과 달리 같은 클래스에 속하는 객체들끼리도 구분한다. 이때 객체들을 구분하는데 필요한 기술이 Object Detection이다.
Object Detection은 Classification + Box localization 하는 문제이다.
* Bonding-Box : (pclass, xmin, ymin, xmax, ymax) or (pclass, xmin, ymin, W, H)
🔷 Two-stage detector (R-CNN들)
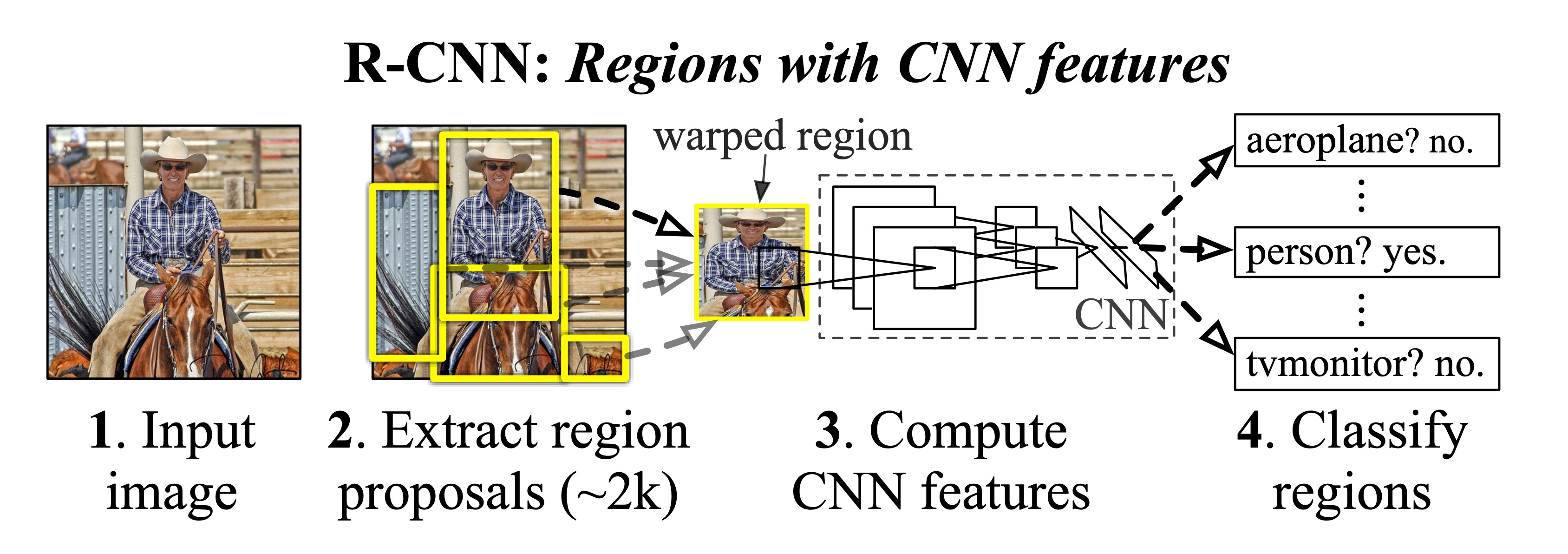
🔸 R-CNN - CVPR 2014
기존의 image classification을 최대한 잘활용하기 위해 간단하게 설계되었다
- 입력영상의 region proposal을 구한다.
- 각 region proposal을 image classification network에 적절한 사이즈로 warpping을 해준다.
- CNN을 통해 카테고리를 분류할 수 있도록 한다.
여기서 CNN은 영상 인식에서 미리 학습된 feature expectation을 사용한다. 단점은 각각 region proposal 마다 모델에 넣어야하므로 속도가 굉장히 느리고, region proposal은 별도의 hand-design된 알고리즘(ex. selective search)을 사용해서 학습을 통해 성능 향상하기엔 한계가 있는 것이다.
🔸 Fast R-CNN - ICCV 2015
영상 전체에 대한 feature를 한번에 추출을 하고, 이를 재활용해서 여러 object들을 detection할 수 있게 한다.
- CNN에서 Convolution layer를 거친 feature map을 미리 뽑아둔다.
- feature map를 재활용하기 위해 RoI pooling layer를 사용한다. 이는 Fixed dimension을 가질 수 있도록 resampling을 한다.
- RoI Projection은 region proposal이 제시한 물체에 후보 위치들을 의미한다.
- 클래스를 위해 softmax 함수, 정밀한 bbox를 위해 bbox regressor를 수행한다.

🔸 Faster R-CNN - NeurlPS 2015
region proposal을 neural network 기반으로 대체를 하고, object detection에서는 최초로 end-to-end 모델이 되었다.
- Anchor boxes
Anchor boxes는 각 위치에서 발생할 것 같은 box들을 미리 정의해둔 후보군이다.
Faster R-CNN에서는 서로 다른 scale 3개와 다른 비율 3개를 사용하여 총 9개의 anchor box를 사용하였다.
여기서 IoU 값이 GT와 비교하여 0.7보다 크면 positive sample, 0.3보다 작으면 negative sample이라 판별하였다.

- IoU (Intersection over Union)
2개의 영역(area)에 overlap을 측정하는 매트랩


- Region Proposal Network (RPN)
Faster R-CNN에서 가장 큰 변화는 Region Proposal 알고리즘인 selective search 대신에 Region Proposal Network (RPN)을 제안하여 대체한 것이다.

feature map에서 Fully Convolutional Layer가 sliding window 방식으로 k개의 anchor box를 고려한다.
각 위치에서 256 dimension의 feature vector를 1개 추출하고, 여기서에 2k scores와 4k coordinates를 추출한다.

Q. 이미 anchor box를 정해뒀는데 왜 regression을 할까?
anchor box를 모든 경우의 수를 고려할 만큼 많이 쓰면 문제가 되지않는다. 하지만 그만큼 계산도 많아질 것이다.
그래서 적당한 양의 anchor box만 미리 만들어놓고, 더 정교한 위치는 regression 문제로 다시 풀게 된다.
classification layer에서는 cross-entropy loss, regression layer에서는 regression loss를 사용한다.
해당 2개의 loss가 RPN을 위한 것이고, 전체 target task를 위한 RoI별 category classification을 위한 loss는 따로 하나 추가되어 전체적으로 end-to-end로 학습된다.
- Non-Maximum Suppression (NMS)
앞서 많은 region proposal가 생성되므로 효과적으로 filtering과 screening를 해주기 위한 방법

<Summary>

🔷 Single-stage detector
정확도를 조금 포기하더라도 속도를 확보하는데 목적을 두고 있다. Region Proposal을 기반으로 한 RoI Pooling을 하지 않고, 곧바로 box regression과 classification을 하기 때문에 구조가 간단하고 속도가 빠르다.

🔸 YOLO (You only look once)
input 이미지를 SxS grid로 나누고, 각 grid에 대해 B개의 Bounding Boxes와 Confidence를 예측하게 된다.
그에 따른 Class probability map을 따로 예측하게 된다. 최종결과는 NMS를 거친 값이 나온다.

일반 CNN의 구조와 동일하다. 7x7x30의 결과가 나온다.
30채널인 이유는 Bounding Box의 anchor B=2, Class C=20로 총 30개가 된다.
SxS는 마지막 레이어의 해상도로 결정된다.

🔸 SSD (Single Shot MultiBox Detector)
Multi-scale object를 더 잘 처리하기 위해서 중간 feature를 각 해상도에 적절한 bounding-box를 출력할 수 있도록 하는 것이다.

VGG를 backbone으로 사용하고, 각 layer에서 만들어진 bounding-box의 총합을 보면 8732가 된다.



🔷 Two-stage detector vs. Single-stage detector
모든 Single-stage detector에서의 문제는 Class imbalance Problem 이다. 이미지 내에서 우리가 찾고자 하는 물제는 아주 일부이고, 나머지는 배경에 해당한다. 이러한 배경은 모델 학습에 도움을 주지 못하면서 계속해서 loss를 발생시켜 모델의 올바른 학습을 방해한다.
🔸 Focal loss
Class imbalance Problem을 해결하기 위한 방법으로, Cross-entropy의 확장이라고 볼 수 있다.
정답을 맞힐 확률이 높은 클래스에 대해서는 낮은 loss gradient를 주고,
정답을 맞힐 확률이 낮은 클래스에 대해서는 높은 loss gradient를 발생시키는 방법이다.

🔸 RetinaNet
이전에 배운 U-Net과 유사한 형태.
Feature Pyramid Networks (FPN) + class/box prediction branches 인 방법.
low-level feature와 high-level feature을 둘다 잘 활용하면서도, 각 scale별로 물체를 잘 찾기위한 multi-scale 구조를 갖기위해 이렇게 설계되었다. Feature Pyramid Networks (FPN) 구조로 각각의 activation map을 차례로 더해가며 class subnet과 box subnet이 따로 구성되어 이들을 거쳐 중간 결과들을 뽑아낸다.

🔷 Detection with Transformer
🔸 DETR
자연어 처리 분야에서 혁명을 일으킨 Transformer 모델을 CV 분야에도 어떻게하면 적용될 수 있을지에 대한 연구가 진행중이다. CNN과 positional encoding로 입력 token을 만들어준다. encoder된 값을 decoder로 넣어준다.
object queries를 활용해서 transformer에게 해당 위치에 있는 물체가 뭔지 질의를 해서 어떤 물체에 대한 class, box를 출력해준다. 없다면 no object를 출력한다.

이외에도 bounding-box를 찾을 때, 물체의 중심점이나 왼쪽위와 오른쪽아래의 양끝점을 찾는 방법을 찾는 연구가 진행되고 있다.
'AI' 카테고리의 다른 글
| [컴퓨터비전] Visualizing CNN (0) | 2023.04.03 |
|---|---|
| [딥러닝] Feature Map, Activation Map, Score Map (0) | 2023.03.30 |
| [컴퓨터비전] Semantic Segmentation (0) | 2023.03.29 |
| [컴퓨터비전] Annotation Data Efficient Learning (0) | 2023.03.28 |
| [컴퓨터비전] Computer Vision 개요, Image Classification (0) | 2023.03.27 |



